1. Introduction
1.1 Preface
本系列博文是和鲸社区的活动《20天吃掉那只PyTorch》学习的笔记,本篇为系列笔记的第五篇——
Pytorch 的中阶 API。该专栏是
Github 上 2.8K
星的项目,在学习该书的过程中可以参考阅读《Python深度学习》一书的第一部分"深度学习基础"内容。
《Python深度学习》这本书是 Keras 之父
Francois Chollet
所著,该书假定读者无任何机器学习知识,以Keras
为工具,使用丰富的范例示范深度学习的最佳实践,该书通俗易懂,全书没有一个数学公式,注重培养读者的深度学习直觉。
《Python深度学习》一书的第一部分的 4
个章节内容如下,预计读者可以在 20 小时之内学完。
- 什么是深度学习
- 神经网络的数学基础
- 神经网络入门
- 机器学习基础
本系列博文的大纲如下:
- 一、PyTorch的建模流程
- 二、PyTorch的核心概念
- 三、PyTorch的层次结构
- 四、PyTorch的低阶API
- 五、PyTorch的中阶API
- 六、PyTorch的高阶API
最后,本博文提供所使用的全部数据,读者可以从下述连接中下载数据:
1.2 Pytorch的中阶API
我们将主要介绍 Pytorch 的如下中阶 API
- 数据管道
- 模型层
- 损失函数
TensorBoard可视化
如果把模型比作一个房子,那么中阶API就是【模型之墙】。
2. Dataset and DataLoader
Pytorch 通常使用 Dataset 和
DataLoader 这两个工具类来构建数据管道。Dataset
定义了数据集的内容,它相当于一个类似列表的数据结构,具有确定的长度,能够用索引获取数据集中的元素。
而 DataLoader 定义了按 batch
加载数据集的方法,它是一个实现了 __iter__
方法的可迭代对象,每次迭代输出一个batch的数据。DataLoader
能够控制 batch 的大小,batch
中元素的采样方法,以及将 batch
结果整理成模型所需输入形式的方法,并且能够使用多进程读取数据。
在绝大部分情况下,用户只需实现 Dataset 的
__len__ 方法和 __getitem__
方法,就可以轻松构建自己的数据集,并用默认数据管道进行加载。
2.1 Dataset和DataLoader概述
2.1.1 获取一个batch数据的步骤
让我们考虑一下从一个数据集中获取一个 batch
的数据需要哪些步骤。
(假定数据集的特征和标签分别表示为张量 X 和
Y,数据集可以表示为 (X,Y), 假定
batch 大小为 m)
首先我们要确定数据集的长度
n。结果类似:
n = 1000。然后我们从
0到n-1的范围中抽样出m个数(batch大小)。假定
m=4, 拿到的结果是一个列表,类似:indices = [1,4,8,9]接着我们从数据集中去取这
m个数对应下标的元素。拿到的结果是一个元组列表,类似:
samples = [(X[1],Y[1]),(X[4],Y[4]),(X[8],Y[8]),(X[9],Y[9])]最后我们将结果整理成两个张量作为输出。
拿到的结果是两个张量,类似
batch = (features,labels), 其中features = torch.stack([X[1],X[4],X[8],X[9]]),labels = torch.stack([Y[1],Y[4],Y[8],Y[9]])
2.1.2 Dataset和DataLoader的功能分工
上述第 1 个步骤确定数据集的长度是由 Dataset
的 __len__ 方法实现的。
第 2 个步骤从0 到 n-1
的范围中抽样出 m 个数的方法是由 DataLoader 的
sampler 和 batch_sampler参数指定的。
sampler参数:指定单个元素抽样方法,一般无需用户设置,程序默认在DataLoader的参数shuffle=True时采用随机抽样,shuffle=False时采用顺序抽样。batch_sampler参数:将多个抽样的元素整理成一个列表,一般无需用户设置,默认方法在DataLoader的参数drop_last=True时会丢弃数据集最后一个长度不能被batch大小整除的批次,在drop_last=False时保留最后一个批次。
第 3 个步骤的核心逻辑根据下标取数据集中的元素 是由
Dataset 的 __getitem__方法实现的。
第 4
个步骤的逻辑由DataLoader的参数collate_fn指定。一般情况下也无需用户设置。
2.1.3 Dataset和DataLoader的主要接口
以下是 Dataset 和 DataLoader
的核心接口逻辑伪代码,不完全和源码一致。
1 | import torch |
2.2 使用 Dataset 创建数据集
Dataset 创建数据集常用的方法有:
使用
torch.utils.data.TensorDataset根据Tensor创建数据集(numpy的array,Pandas的DataFrame需要先转换成Tensor)。使用
torchvision.datasets.ImageFolder根据图片目录创建图片数据集。继承
torch.utils.data.Dataset创建自定义数据集。
此外,还可以通过
torch.utils.data.random_split将一个数据集分割成多份,常用于分割训练集,验证集和测试集。- 调用
Dataset的加法运算符(+)将多个数据集合并成一个数据集。
2.2.1 根据Tensor创建数据集
1 | import numpy as np |
根据
Tensor创建数据集1
2
3
4
5
6
7
8
9
10
11
12
13
14# 根据Tensor创建数据集
from sklearn import datasets
iris = datasets.load_iris()
ds_iris = TensorDataset(torch.tensor(iris.data),torch.tensor(iris.target))
# 分割成训练集和预测集
n_train = int(len(ds_iris)*0.8)
n_valid = len(ds_iris) - n_train
ds_train,ds_valid = random_split(ds_iris,[n_train,n_valid])
print(type(ds_iris))
print(type(ds_train))Results:
<class 'torch.utils.data.dataset.TensorDataset'> <class 'torch.utils.data.dataset.Subset'>使用
DataLoader加载数据集1
2
3
4
5
6# 使用DataLoader加载数据集
dl_train,dl_valid = DataLoader(ds_train,batch_size = 8),DataLoader(ds_valid,batch_size = 8)
for features,labels in dl_train:
print(features,labels)
breakResults:
tensor([[6.5000, 2.8000, 4.6000, 1.5000], [5.4000, 3.4000, 1.5000, 0.4000], [5.0000, 2.3000, 3.3000, 1.0000], [7.2000, 3.0000, 5.8000, 1.6000], [5.2000, 3.5000, 1.5000, 0.2000], [5.0000, 3.3000, 1.4000, 0.2000], [6.6000, 3.0000, 4.4000, 1.4000], [5.7000, 2.6000, 3.5000, 1.0000]], dtype=torch.float64) tensor([1, 0, 1, 2, 0, 0, 1, 1], dtype=torch.int32)演示加法运算符(
+)的合并作用1
2
3
4
5
6
7
8
9# 演示加法运算符(`+`)的合并作用
ds_data = ds_train + ds_valid
print('len(ds_train) = ',len(ds_train))
print('len(ds_valid) = ',len(ds_valid))
print('len(ds_train+ds_valid) = ',len(ds_data))
print(type(ds_data))Results:
len(ds_train) = 120 len(ds_valid) = 30 len(ds_train+ds_valid) = 150 <class 'torch.utils.data.dataset.ConcatDataset'>
2.2.2 根据图片目录创建图片数据集
1 | import numpy as np |
Open image
1
2
3data_dir = '../data/'
img = Image.open(data_dir + '/cat.jpeg')
imgResults:

旋转
1
2# 随机数值翻转
transforms.RandomVerticalFlip()(img)Results:
图片增强
1
2
3
4
5
6
7
8
9
10
11
12
13
14# 定义图片增强操作
transform_train = transforms.Compose([
transforms.RandomHorizontalFlip(), #随机水平翻转
transforms.RandomVerticalFlip(), #随机垂直翻转
transforms.RandomRotation(45), #随机在45度角度内旋转
transforms.ToTensor() #转换成张量
]
)
transform_valid = transforms.Compose([
transforms.ToTensor()
]
)根据图片目录创建数据集
1
2
3
4
5
6
7# 根据图片目录创建数据集
ds_train = datasets.ImageFolder(data_dir+ "cifar2/train/",
transform = transform_train)
ds_valid = datasets.ImageFolder(data_dir+ "cifar2/test/",
transform = transform_train)
print(ds_train.class_to_idx)Results:
{'0_airplane': 0, '1_automobile': 1}Note:之前已经提到,
target_transform参数中的匿名函数会导致后面出错,此处予以删除,后面的部分随之修改。使用
DataLoader加载数据集1
2
3
4# 使用DataLoader加载数据集
dl_train = DataLoader(ds_train,batch_size = 50,shuffle = True,num_workers=3)
dl_valid = DataLoader(ds_valid,batch_size = 50,shuffle = True,num_workers=3)查看大小
1
2
3
4for features,labels in dl_train:
print(features.shape)
print(labels.shape)
breakResults:
torch.Size([50, 3, 32, 32]) torch.Size([50])
2.2.3 创建自定义数据集
下面通过继承 Dataset 类创建 imdb
文本分类任务的自定义数据集。
大概思路如下:
- 对训练集文本分词构建词典。
- 然后将训练集文本和测试集文本数据转换成
token单词编码。 - 接着将转换成单词编码的训练集数据和测试集数据按样本分割成多个文件,一个文件代表一个样本。
- 我们可以根据文件名列表获取对应序号的样本内容,从而构建
Dataset数据集。
1 | import numpy as np |
首先我们构建词典,并保留最高频的
MAX_WORDS个词。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27##构建词典
word_count_dict = {}
#清洗文本
def clean_text(text):
lowercase = text.lower().replace("\n"," ")
stripped_html = re.sub('<br />', ' ',lowercase)
cleaned_punctuation = re.sub('[%s]'%re.escape(string.punctuation),'',stripped_html)
return cleaned_punctuation
with open(train_data_path,"r",encoding = 'utf-8') as f:
for line in f:
label,text = line.split("\t")
cleaned_text = clean_text(text)
for word in cleaned_text.split(" "):
word_count_dict[word] = word_count_dict.get(word,0)+1
df_word_dict = pd.DataFrame(pd.Series(word_count_dict,name = "count"))
df_word_dict = df_word_dict.sort_values(by = "count",ascending =False)
df_word_dict = df_word_dict[0:MAX_WORDS-2] #
df_word_dict["word_id"] = range(2,MAX_WORDS) #编号0和1分别留给未知词<unkown>和填充<padding>
word_id_dict = df_word_dict["word_id"].to_dict()
df_word_dict.head(10)Results:
count
word_id
the
268230
2
and
129713
3
a
129479
4
of
116497
5
to
108296
6
is
85615
7
84074
8
in
74715
9
it
62587
10
i
60837
11
然后我们利用构建好的词典,将文本转换成
token序号。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24#转换token
# 填充文本
def pad(data_list,pad_length):
padded_list = data_list.copy()
if len(data_list)> pad_length:
padded_list = data_list[-pad_length:]
if len(data_list)< pad_length:
padded_list = [1]*(pad_length-len(data_list))+data_list
return padded_list
def text_to_token(text_file,token_file):
with open(text_file,"r",encoding = 'utf-8') as fin,\
open(token_file,"w",encoding = 'utf-8') as fout:
for line in fin:
label,text = line.split("\t")
cleaned_text = clean_text(text)
word_token_list = [word_id_dict.get(word, 0) for word in cleaned_text.split(" ")]
pad_list = pad(word_token_list,MAX_LEN)
out_line = label+"\t"+" ".join([str(x) for x in pad_list])
fout.write(out_line+"\n")
text_to_token(train_data_path,train_token_path)
text_to_token(test_data_path,test_token_path)接着将
token文本按照样本分割,每个文件存放一个样本的数据。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21# 分割样本
import os
if not os.path.exists(train_samples_path):
os.mkdir(train_samples_path)
if not os.path.exists(test_samples_path):
os.mkdir(test_samples_path)
def split_samples(token_path,samples_dir):
with open(token_path,"r",encoding = 'utf-8') as fin:
i = 0
for line in fin:
with open(samples_dir+"%d.txt"%i,"w",encoding = "utf-8") as fout:
fout.write(line)
i = i+1
split_samples(train_token_path,train_samples_path)
split_samples(test_token_path,test_samples_path)
print(os.listdir(train_samples_path)[0:100])Results:
1
['0.txt', '1.txt', '10.txt', '100.txt', '1000.txt', '10000.txt', '10001.txt', '10002.txt', '10003.txt', '10004.txt', '10005.txt', '10006.txt', '10007.txt', '10008.txt', '10009.txt', '1001.txt', '10010.txt', '10011.txt', '10012.txt', '10013.txt', '10014.txt', '10015.txt', '10016.txt', '10017.txt', '10018.txt', '10019.txt', '1002.txt', '10020.txt', '10021.txt', '10022.txt', '10023.txt', '10024.txt', '10025.txt', '10026.txt', '10027.txt', '10028.txt', '10029.txt', '1003.txt', '10030.txt', '10031.txt', '10032.txt', '10033.txt', '10034.txt', '10035.txt', '10036.txt', '10037.txt', '10038.txt', '10039.txt', '1004.txt', '10040.txt', '10041.txt', '10042.txt', '10043.txt', '10044.txt', '10045.txt', '10046.txt', '10047.txt', '10048.txt', '10049.txt', '1005.txt', '10050.txt', '10051.txt', '10052.txt', '10053.txt', '10054.txt', '10055.txt', '10056.txt', '10057.txt', '10058.txt', '10059.txt', '1006.txt', '10060.txt', '10061.txt', '10062.txt', '10063.txt', '10064.txt', '10065.txt', '10066.txt', '10067.txt', '10068.txt', '10069.txt', '1007.txt', '10070.txt', '10071.txt', '10072.txt', '10073.txt', '10074.txt', '10075.txt', '10076.txt', '10077.txt', '10078.txt', '10079.txt', '1008.txt', '10080.txt', '10081.txt', '10082.txt', '10083.txt', '10084.txt', '10085.txt', '10086.txt']
一切准备就绪,我们可以创建数据集
Dataset, 从文件名称列表中读取文件内容了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import os
class imdbDataset(Dataset):
def __init__(self,samples_dir):
self.samples_dir = samples_dir
self.samples_paths = os.listdir(samples_dir)
def __len__(self):
return len(self.samples_paths)
def __getitem__(self,index):
path = self.samples_dir + self.samples_paths[index]
with open(path,"r",encoding = "utf-8") as f:
line = f.readline()
label,tokens = line.split("\t")
label = torch.tensor([float(label)],dtype = torch.float)
feature = torch.tensor([int(x) for x in tokens.split(" ")],dtype = torch.long)
return (feature,label)
ds_train = imdbDataset(train_samples_path)
ds_test = imdbDataset(test_samples_path)
print(len(ds_train))
print(len(ds_test))Results:
20000 5000
DataLoader
1
2
3
4
5
6
7dl_train = DataLoader(ds_train,batch_size = BATCH_SIZE,shuffle = True)
dl_test = DataLoader(ds_test,batch_size = BATCH_SIZE)
for features,labels in dl_train:
print(features)
print(labels)
breakResults:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27tensor([[ 1, 1, 1, ..., 1442, 8, 8],
[ 24, 270, 28, ..., 766, 99, 8],
[ 1, 1, 1, ..., 124, 422, 8],
...,
[ 1, 1, 1, ..., 1519, 946, 8],
[ 1, 1, 1, ..., 775, 254, 8],
[ 498, 3, 1656, ..., 0, 0, 8]])
tensor([[1.],
[1.],
[1.],
[0.],
[1.],
[1.],
[0.],
[1.],
[0.],
[0.],
[0.],
[1.],
[1.],
[1.],
[1.],
[1.],
[0.],
[0.],
[1.],
[0.]])
2.2.4 搭建模型
构建模型测试一下数据集管道是否可用。
Create model
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35import torch
from torch import nn
import importlib
from torchkeras import Model,summary
class Net(Model):
def __init__(self):
super(Net, self).__init__()
#设置padding_idx参数后将在训练过程中将填充的token始终赋值为0向量
self.embedding = nn.Embedding(num_embeddings = MAX_WORDS,embedding_dim = 3,padding_idx = 1)
self.conv = nn.Sequential()
self.conv.add_module("conv_1",nn.Conv1d(in_channels = 3,out_channels = 16,kernel_size = 5))
self.conv.add_module("pool_1",nn.MaxPool1d(kernel_size = 2))
self.conv.add_module("relu_1",nn.ReLU())
self.conv.add_module("conv_2",nn.Conv1d(in_channels = 16,out_channels = 128,kernel_size = 2))
self.conv.add_module("pool_2",nn.MaxPool1d(kernel_size = 2))
self.conv.add_module("relu_2",nn.ReLU())
self.dense = nn.Sequential()
self.dense.add_module("flatten",nn.Flatten())
self.dense.add_module("linear",nn.Linear(6144,1))
self.dense.add_module("sigmoid",nn.Sigmoid())
def forward(self,x):
x = self.embedding(x).transpose(1,2)
x = self.conv(x)
y = self.dense(x)
return y
model = Net()
print(model)
model.summary(input_shape = (200,),input_dtype = torch.LongTensor)Results:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39Net(
(embedding): Embedding(10000, 3, padding_idx=1)
(conv): Sequential(
(conv_1): Conv1d(3, 16, kernel_size=(5,), stride=(1,))
(pool_1): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(relu_1): ReLU()
(conv_2): Conv1d(16, 128, kernel_size=(2,), stride=(1,))
(pool_2): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(relu_2): ReLU()
)
(dense): Sequential(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear): Linear(in_features=6144, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Embedding-1 [-1, 200, 3] 30,000
Conv1d-2 [-1, 16, 196] 256
MaxPool1d-3 [-1, 16, 98] 0
ReLU-4 [-1, 16, 98] 0
Conv1d-5 [-1, 128, 97] 4,224
MaxPool1d-6 [-1, 128, 48] 0
ReLU-7 [-1, 128, 48] 0
Flatten-8 [-1, 6144] 0
Linear-9 [-1, 1] 6,145
Sigmoid-10 [-1, 1] 0
================================================================
Total params: 40,625
Trainable params: 40,625
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.000763
Forward/backward pass size (MB): 0.287796
Params size (MB): 0.154972
Estimated Total Size (MB): 0.443531
----------------------------------------------------------------Compile model
1
2
3
4
5
6
7
8
9# 编译模型
def accuracy(y_pred,y_true):
y_pred = torch.where(y_pred>0.5,torch.ones_like(y_pred,dtype = torch.float32),
torch.zeros_like(y_pred,dtype = torch.float32))
acc = torch.mean(1-torch.abs(y_true-y_pred))
return acc
model.compile(loss_func = nn.BCELoss(),optimizer= torch.optim.Adagrad(model.parameters(),lr = 0.02),
metrics_dict={"accuracy":accuracy})Trainning model
1
2# 训练模型
dfhistory = model.fit(10,dl_train,dl_val=dl_test,log_step_freq= 200)Results:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25Start Training ...
================================================================================2022-02-07 13:39:22
{'step': 200, 'loss': 0.87, 'accuracy': 0.516}
{'step': 400, 'loss': 0.778, 'accuracy': 0.532}
{'step': 600, 'loss': 0.742, 'accuracy': 0.546}
{'step': 800, 'loss': 0.722, 'accuracy': 0.56}
{'step': 1000, 'loss': 0.706, 'accuracy': 0.574}
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 1 | 0.706 | 0.574 | 0.641 | 0.628 |
+-------+-------+----------+----------+--------------+
...
+-------+-------+----------+----------+--------------+
| epoch | loss | accuracy | val_loss | val_accuracy |
+-------+-------+----------+----------+--------------+
| 10 | 0.319 | 0.867 | 0.486 | 0.775 |
+-------+-------+----------+----------+--------------+
================================================================================2022-02-07 13:45:27
Finished Training...
2.3 使用DataLoader加载数据集
DataLoader 能够控制 batch
的大小,batch 中元素的采样方法,以及将 batch
结果整理成模型所需输入形式的方法,并且能够使用多进程读取数据。
DataLoader 的函数签名如下。
1 | DataLoader( |
一般情况下,我们仅仅会配置 dataset,
batch_size, shuffle, num_workers,
drop_last 这五个参数,其他参数使用默认值即可。
DataLoader 除了可以加载我们前面讲的
torch.utils.data.Dataset 外,还能够加载另外一种数据集
torch.utils.data.IterableDataset。和 Dataset
数据集相当于一种列表结构不同,IterableDataset
相当于一种迭代器结构。 它更加复杂,一般较少使用。
dataset: 数据集batch_size: 批次大小shuffle: 是否乱序sampler: 样本采样函数,一般无需设置。batch_sampler: 批次采样函数,一般无需设置。num_workers: 使用多进程读取数据,设置的进程数。collate_fn: 整理一个批次数据的函数。pin_memory: 是否设置为锁业内存。默认为False,锁业内存不会使用虚拟内存(硬盘),从锁业内存拷贝到GPU上速度会更快。drop_last: 是否丢弃最后一个样本数量不足batch_size批次数据。timeout: 加载一个数据批次的最长等待时间,一般无需设置。worker_init_fn: 每个worker中dataset的初始化函数,常用于IterableDataset。一般不使用。Pipeline
1
2
3
4
5
6
7
8
9
10#构建输入数据管道
ds = TensorDataset(torch.arange(1,50))
dl = DataLoader(ds,
batch_size = 10,
shuffle= True,
num_workers=2,
drop_last = True)
#迭代数据
for batch, in dl:
print(batch)Results:
tensor([26, 29, 12, 45, 4, 16, 18, 8, 31, 36]) tensor([48, 15, 21, 37, 14, 2, 22, 11, 17, 20]) tensor([41, 3, 35, 24, 5, 39, 27, 40, 19, 23]) tensor([43, 30, 9, 34, 7, 33, 38, 42, 6, 46])
3. 模型层 layers
深度学习模型一般由各种模型层组合而成。torch.nn
中内置了非常丰富的各种模型层。它们都属于 nn.Module
的子类,具备参数管理功能。
例如:
- nn.Linear, nn.Flatten, nn.Dropout, nn.BatchNorm2d
- nn.Conv2d,nn.AvgPool2d,nn.Conv1d,nn.ConvTranspose2d
- nn.Embedding,nn.GRU,nn.LSTM
- nn.Transformer
如果这些内置模型层不能够满足需求,我们也可以通过继承
nn.Module 基类构建自定义的模型层。
实际上,pytorch 不区分模型和模型层,都是通过继承
nn.Module 进行构建。因此,我们只要继承
nn.Module 基类并实现 forward
方法即可自定义模型层。
3.1 内置模型层
1 | import numpy as np |
3.1.1 基础层
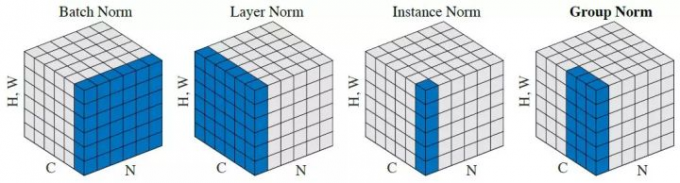
nn.Linear:全连接层。参数个数 = 输入层特征数× 输出层特征数(weight)+ 输出层特征数(bias)nn.Flatten:压平层,用于将多维张量样本压成一维张量样本。nn.BatchNorm1d:一维批标准化层。通过线性变换将输入批次缩放平移到稳定的均值和标准差。可以增强模型对输入不同分布的适应性,加快模型训练速度,有轻微正则化效果。一般在激活函数之前使用。可以用afine参数设置该层是否含有可以训练的参数。nn.BatchNorm2d:二维批标准化层。nn.BatchNorm3d:三维批标准化层。nn.Dropout:一维随机丢弃层。一种正则化手段。nn.Dropout2d:二维随机丢弃层。nn.Dropout3d:三维随机丢弃层。nn.Threshold:限幅层。当输入大于或小于阈值范围时,截断之。nn.ConstantPad2d: 二维常数填充层。对二维张量样本填充常数扩展长度。nn.ReplicationPad1d: 一维复制填充层。对一维张量样本通过复制边缘值填充扩展长度。nn.ZeroPad2d:二维零值填充层。对二维张量样本在边缘填充0值.nn.GroupNorm:组归一化。一种替代批归一化的方法,将通道分成若干组进行归一。不受batch大小限制,据称性能和效果都优于BatchNorm。nn.LayerNorm:层归一化。较少使用。nn.InstanceNorm2d: 样本归一化。较少使用。
各种归一化技术参考如下知乎文章《FAIR何恺明等人提出组归一化:替代批归一化,不受批量大小限制》:https://zhuanlan.zhihu.com/p/34858971
3.1.2 卷积网络相关层
nn.Conv1d:普通一维卷积,常用于文本。参数个数 = 输入通道数×卷积核尺寸(如3)×卷积核个数 + 卷积核尺寸(如3)nn.Conv2d:普通二维卷积,常用于图像。参数个数 = 输入通道数×卷积核尺寸(如 3 \times 3)×卷积核个数 + 卷积核尺寸(如 3 \times 3 )通过调整
dilation参数大于1,可以变成空洞卷积,增大卷积核感受野。通过调整
groups参数不为1,可以变成分组卷积。分组卷积中不同分组使用相同的卷积核,显著减少参数数量。当
groups参数等于通道数时,相当于tensorflow中的二维深度卷积层tf.keras.layers.DepthwiseConv2D。利用分组卷积和
1乘1卷积的组合操作,可以构造相当于Keras中的二维深度可分离卷积层tf.keras.layers.SeparableConv2D。nn.Conv3d:普通三维卷积,常用于视频。参数个数 = 输入通道数×卷积核尺寸(如 3\times 3 \times 3)×卷积核个数 + 卷积核尺寸(如 3\times 3 \times 3) 。nn.MaxPool1d: 一维最大池化。nn.MaxPool2d:二维最大池化。一种下采样方式。没有需要训练的参数。nn.MaxPool3d:三维最大池化。nn.AdaptiveMaxPool2d:二维自适应最大池化。无论输入图像的尺寸如何变化,输出的图像尺寸是固定的。该函数的实现原理,大概是通过输入图像的尺寸和要得到的输出图像的尺寸来反向推算池化算子的
padding,stride等参数。nn.FractionalMaxPool2d:二维分数最大池化。普通最大池化通常输入尺寸是输出的整数倍。而分数最大池化则可以不必是整数。分数最大池化使用了一些随机采样策略,有一定的正则效果,可以用它来代替普通最大池化和Dropout层。nn.AvgPool2d:二维平均池化。nn.AdaptiveAvgPool2d:二维自适应平均池化。无论输入的维度如何变化,输出的维度是固定的。nn.ConvTranspose2d:二维卷积转置层,俗称反卷积层。并非卷积的逆操作,但在卷积核相同的情况下,当其输入尺寸是卷积操作输出尺寸的情况下,卷积转置的输出尺寸恰好是卷积操作的输入尺寸。在语义分割中可用于上采样。nn.Upsample:上采样层,操作效果和池化相反。可以通过mode参数控制上采样策略为"nearest"最邻近策略或"linear"线性插值策略。nn.Unfold:滑动窗口提取层。其参数和卷积操作nn.Conv2d相同。实际上,卷积操作可以等价于nn.Unfold和nn.Linear以及nn.Fold的一个组合。其中
nn.Unfold操作可以从输入中提取各个滑动窗口的数值矩阵,并将其压平成一维。利用nn.Linear将nn.Unfold的输出和卷积核做乘法后,再使用nn.Fold操作将结果转换成输出图片形状。nn.Fold:逆滑动窗口提取层。
3.1.3 循环网络相关层
nn.Embedding:嵌入层。一种比Onehot更加有效的对离散特征进行编码的方法。一般用于将输入中的单词映射为稠密向量。嵌入层的参数需要学习。nn.LSTM:长短记忆循环网络层【支持多层】,最普遍使用的循环网络层。具有携带轨道,遗忘门,更新门,输出门。可以较为有效地缓解梯度消失问题,从而能够适用长期依赖问题。设置bidirectional = True时可以得到Bi-LSTM。需要注意的时,默认的输入和输出形状是(seq,batch,feature), 如果需要将batch维度放在第0维,则要设置batch_first参数设置为True。nn.GRU:门控循环网络层【支持多层】。LSTM的低配版,不具有携带轨道,参数数量少于LSTM,训练速度更快。nn.RNN:简单循环网络层【支持多层】。容易存在梯度消失,不能够适用长期依赖问题。一般较少使用。nn.LSTMCell:长短记忆循环网络单元。和nn.LSTM在整个序列上迭代相比,它仅在序列上迭代一步。一般较少使用。nn.GRUCell:门控循环网络单元。和nn.GRU在整个序列上迭代相比,它仅在序列上迭代一步。一般较少使用。nn.RNNCell:简单循环网络单元。和nn.RNN在整个序列上迭代相比,它仅在序列上迭代一步。一般较少使用。
3.1.4 Transformer相关层
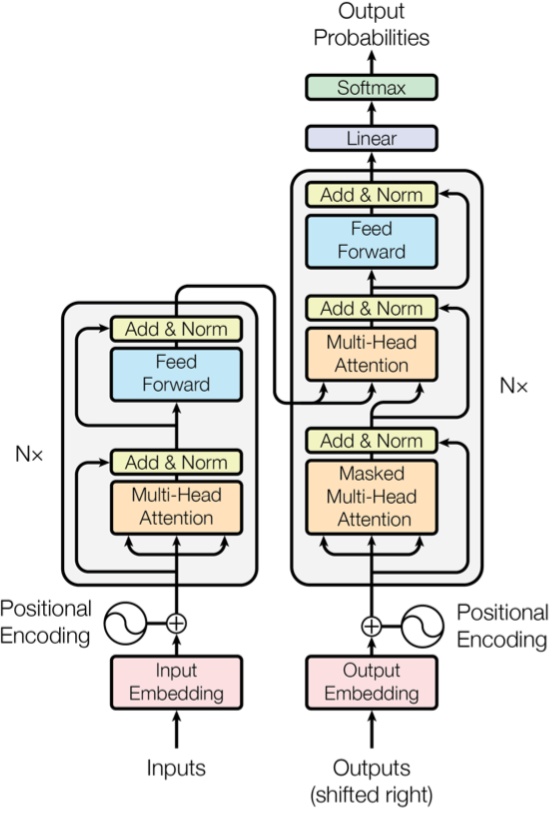
nn.Transformer:Transformer网络结构。Transformer网络结构是替代循环网络的一种结构,解决了循环网络难以并行,难以捕捉长期依赖的缺陷。它是目前NLP任务的主流模型的主要构成部分。Transformer网络结构由TransformerEncoder编码器和TransformerDecoder解码器组成。编码器和解码器的核心是MultiheadAttention多头注意力层。nn.TransformerEncoder:Transformer编码器结构。由多个nn.TransformerEncoderLayer编码器层组成。nn.TransformerDecoder:Transformer解码器结构。由多个nn.TransformerDecoderLayer解码器层组成。nn.TransformerEncoderLayer:Transformer的编码器层。nn.TransformerDecoderLayer:Transformer的解码器层。nn.MultiheadAttention:多头注意力层。
Transformer
原理介绍可以参考如下知乎文章《详解Transformer(Attention Is All You
Need)》:https://zhuanlan.zhihu.com/p/48508221
3.2 自定义模型层
如果 Pytorch
的内置模型层不能够满足需求,我们也可以通过继承 nn.Module
基类构建自定义的模型层。
实际上,pytorch 不区分模型和模型层,都是通过继承
nn.Module 进行构建。因此,我们只要继承
nn.Module 基类并实现 forward
方法即可自定义模型层。下面是 Pytorch 的
nn.Linear 层的源码,我们可以仿照它来自定义模型层。
1 | import torch |
查看输出维度
1
2
3
4linear = nn.Linear(20, 30)
inputs = torch.randn(128, 20)
output = linear(inputs)
print(output.size())Results:
torch.Size([128, 30])
4. 损失函数 loss
一般来说,监督学习的目标函数由损失函数和正则化项组成。
1 | Objective = Loss + Regularization |
Pytorch 中的损失函数一般在训练模型时候指定。
Note:Pytorch 中内置的损失函数的参数和
tensorflow 不同,是 y_pred
在前,y_true 在后,而 Tensorflow 是
y_true 在前,y_pred 在后。
回归模型
对于回归模型,通常使用的内置损失函数是均方损失函数
nn.MSELoss。二分类问题
对于二分类模型,通常使用的是二元交叉熵损失函数
nn.BCELoss(输入已经是sigmoid激活函数之后的结果) ,或者nn.BCEWithLogitsLoss(输入尚未经过nn.Sigmoid激活函数) 。多分类问题
对于多分类模型,一般推荐使用交叉熵损失函数
nn.CrossEntropyLoss。(y_true需要是一维的,是类别编码。y_pred未经过nn.Softmax激活。)此外,如果多分类的
y_pred经过了nn.LogSoftmax激活,可以使用nn.NLLLoss损失函数(The negative log likelihood loss),这种方法和直接使用nn.CrossEntropyLoss等价。自定义损失函数
如果有需要,也可以自定义损失函数,自定义损失函数需要接收两个张量
y_pred,y_true作为输入参数,并输出一个标量作为损失函数值。
Pytorch
中的正则化项一般通过自定义的方式和损失函数一起添加作为目标函数。如果仅仅使用
L2 正则化,也可以利用优化器的 weight_decay
参数来实现相同的效果。
4.1 内置损失函数
内置的损失函数一般有 类的实现 和 函数的实现 两种形式。
如:nn.BCE 和 F.binary_cross_entropy
都是二元交叉熵损失函数,前者是类的实现形式,后者是函数的实现形式。
实际上,类的实现形式通常是调用函数的实现形式并用
nn.Module
封装后得到的。一般我们常用的是类的实现形式。它们封装在
torch.nn 模块下,并且类名以 Loss
结尾。常用的一些内置损失函数说明如下。
nn.MSELoss:均方误差损失,也叫做L2损失,用于回归nn.L1Loss:L1损失,也叫做绝对值误差损失,用于回归nn.SmoothL1Loss:(平滑L1损失,当输入在-1到1之间时,平滑为L2损失,用于回归nn.BCELoss:二元交叉熵,用于二分类,输入已经过nn.Sigmoid激活,对 不平衡数据集 可以用weigths参数调整类别权重nn.BCEWithLogitsLoss:二元交叉熵,用于二分类,输入未经过nn.Sigmoid激活nn.CrossEntropyLoss:交叉熵,用于多分类,要求label为稀疏编码,输入未经过nn.Softmax激活,对 不平衡数据集 可以用weigths参数调整类别权重nn.NLLLoss:负对数似然损失,用于多分类,要求label为稀疏编码,输入经过nn.LogSoftmax激活nn.CosineSimilarity:余弦相似度,可用于多分类nn.AdaptiveLogSoftmaxWithLoss:一种适合非常多类别且类别分布很不均衡的损失函数,会自适应地将多个小类别合成一个cluster
更多损失函数的介绍参考如下知乎文章:《PyTorch的十八个损失函数》
1 | import numpy as np |
Results:
tensor(0.5493)
tensor(0.5493)4.2 自定义损失函数
自定义损失函数接收两个张量 y_pred, y_true
作为输入参数,并输出一个标量作为损失函数值。
也可以对 nn.Module 进行子类化,重写 forward
方法实现损失的计算逻辑,从而得到损失函数的类的实现。
Focal Loss下面是一个
Focal Loss的自定义实现示范。Focal Loss是一种对binary_crossentropy的改进损失函数形式。它在 样本不均衡 和存在较多易分类的样本时相比binary_crossentropy具有明显的优势。它有两个可调参数,
alpha参数和gamma参数。其中alpha参数主要用于衰减负样本的权重,gamma参数主要用于衰减容易训练样本的权重。从而让模型更加聚焦在正样本和困难样本上。这就是为什么这个损失函数叫做Focal Loss。
详见:《5分钟理解Focal Loss与GHM——解决样本不平衡利器》
focal\_loss(y,p) = \begin{cases} -\alpha (1-p)^{\gamma}\log(p) & \text{if y = 1}\\ -(1-\alpha) p^{\gamma}\log(1-p) & \text{if y = 0} \end{cases}
1 | class FocalLoss(nn.Module): |
Example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20#困难样本
y_pred_hard = torch.tensor([[0.5],[0.5]])
y_true_hard = torch.tensor([[1.0],[0.0]])
#容易样本
y_pred_easy = torch.tensor([[0.9],[0.1]])
y_true_easy = torch.tensor([[1.0],[0.0]])
focal_loss = FocalLoss()
bce_loss = nn.BCELoss()
print("focal_loss(hard samples):", focal_loss(y_pred_hard,y_true_hard))
print("bce_loss(hard samples):", bce_loss(y_pred_hard,y_true_hard))
print("focal_loss(easy samples):", focal_loss(y_pred_easy,y_true_easy))
print("bce_loss(easy samples):", bce_loss(y_pred_easy,y_true_easy))
#可见 focal_loss让容易样本的权重衰减到原来的 0.0005/0.1054 = 0.00474
#而让困难样本的权重只衰减到原来的 0.0866/0.6931=0.12496
# 因此相对而言,focal_loss可以衰减容易样本的权重。Results:
focal_loss(hard samples): tensor(0.0866) bce_loss(hard samples): tensor(0.6931) focal_loss(easy samples): tensor(0.0005) bce_loss(easy samples): tensor(0.1054)
Note:可见 focal_loss
让容易样本的权重衰减到原来的
0.0005/0.1054 = 0.00474,而让困难样本的权重只衰减到原来的
0.0866/0.6931=0.12496,因此相对而言,focal_loss
可以衰减容易样本的权重。
FocalLoss 的使用完整范例可以参考下面中 自定义
L1 和 L2 正则化项
中的范例,该范例既演示了自定义正则化项的方法,也演示了
FocalLoss 的使用方法。
4.3 自定义L1和L2正则化项
通常认为 L1
正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择。而
L2
正则化可以防止模型过拟合(overfitting)。一定程度上,L1
也可以防止过拟合。
下面以一个二分类问题为例,演示给模型的目标函数添加自定义
L1 和 L2
正则化项的方法。这个范例同时演示了上一个部分的 FocalLoss
的使用。
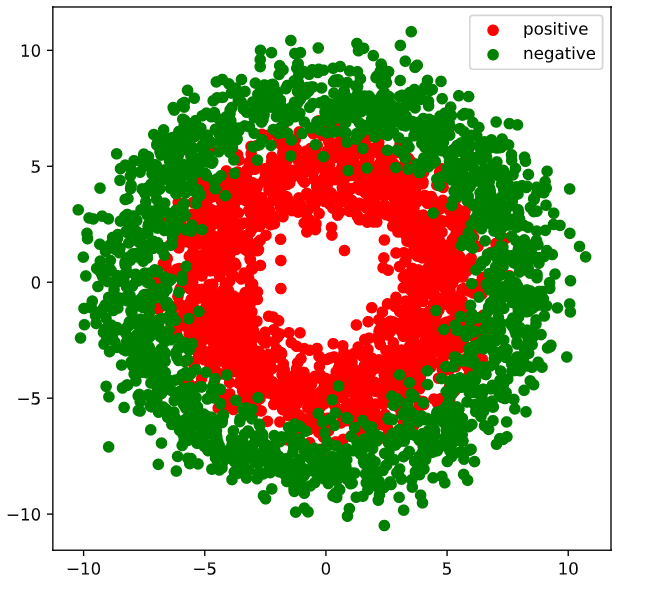
4.3.1 Prepare data
1 | import numpy as np |
Results:
Dataset
1
2
3
4
5ds = TensorDataset(X,Y)
ds_train,ds_valid = torch.utils.data.random_split(ds,[int(len(ds)*0.7),len(ds)-int(len(ds)*0.7)])
dl_train = DataLoader(ds_train,batch_size = 100,shuffle=True,num_workers=2)
dl_valid = DataLoader(ds_valid,batch_size = 100,num_workers=2)
4.3.2 Define model
1 | class DNNModel(torchkeras.Model): |
Results:
1 | ---------------------------------------------------------------- |
4.3.3 Training model
1 | # 准确率 |
Results:
1 | Start Training ... |
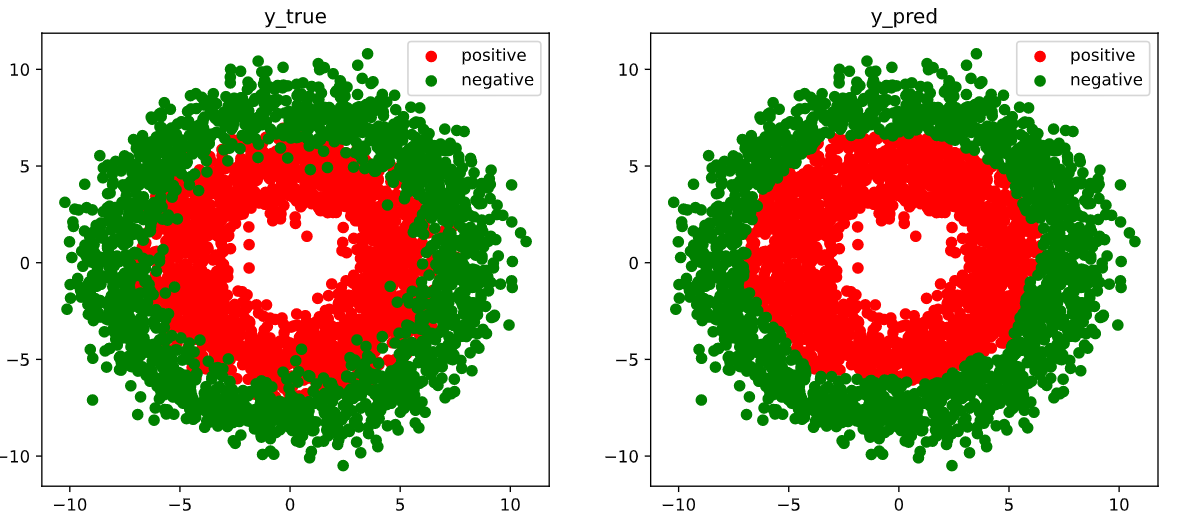
4.3.4 Visualization
1 | # 结果可视化 |
Results:
4.4 通过优化器实现L2正则化
如果仅仅需要使用 L2 正则化,那么也可以利用优化器的
weight_decay 参数来实现。weight_decay
参数可以设置参数在训练过程中的衰减,这和 L2
正则化的作用效果等价。
1 | before L2 regularization: |
Pytorch 的优化器支持一种称之为
Per-parameter options
的操作,就是对每一个参数进行特定的学习率,权重衰减率指定,以满足更为细致的要求。
1 | weight_params = [param for name, param in model.named_parameters() if "bias" not in name] |
5. TensorBoard可视化
在我们的炼丹过程中,如果能够使用丰富的图像来展示模型的结构,指标的变化,参数的分布,输入的形态等信息,无疑会提升我们对问题的洞察力,并增加许多炼丹的乐趣。
TensorBoard 正是这样一个神奇的炼丹可视化辅助工具。它原是
TensorFlow 的小弟,但它也能够很好地和 Pytorch
进行配合。甚至在 Pytorch 中使用TensorBoard 比
TensorFlow 中使用 TensorBoard
还要来的更加简单和自然。
Pytorch 中利用 TensorBoard
可视化的大概过程如下:
- 首先在
Pytorch中指定一个目录创建一个torch.utils.tensorboard.SummaryWriter日志写入器。 - 然后根据需要可视化的信息,利用日志写入器将相应信息日志写入我们指定的目录。
- 最后就可以传入日志目录作为参数启动
TensorBoard,然后就可以在TensorBoard中愉快地看片了。
我们主要介绍 Pytorch 中利用 TensorBoard
进行如下方面信息的可视化的方法。
- 可视化模型结构:
writer.add_graph - 可视化指标变化:
writer.add_scalar - 可视化参数分布:
writer.add_histogram - 可视化原始图像:
writer.add_image 或 writer.add_images - 可视化人工绘图:
writer.add_figure
5.1 可视化模型结构
1 | import torch |
Results:
1 | Net( |
1 | summary(net,input_shape= (3,32,32)) |
Results:
1 | ---------------------------------------------------------------- |
`创建日志写入器
1
2
3writer = SummaryWriter(data_dir + '/tensorboard1')
writer.add_graph(net,input_to_model = torch.rand(1,3,32,32))
writer.close()1
2
3# %load_ext tensorboard
%reload_ext tensorboard
#%tensorboard --logdir ./data/tensorboard1
2
3from tensorboard import notebook
#查看启动的tensorboard程序
notebook.list()Results:
Known TensorBoard instances: - port 6006: logdir ../data/tensorboard (started 18:40:59 ago; pid 12512)启动
tensorboard1
2
3
4#启动tensorboard程序
notebook.start("--logdir ../data/tensorboard1")
#等价于在命令行中执行 tensorboard --logdir ./data/tensorboard
#可以在浏览器中打开 http://localhost:6006/ 查看
5.2 可视化指标变化
有时候在训练过程中,如果能够实时动态地查看 loss 和各种
metric
的变化曲线,那么无疑可以帮助我们更加直观地了解模型的训练情况。
Note:writer.add_scalar
仅能对标量的值的变化进行可视化。因此它一般用于对loss 和
metric 的变化进行可视化分析。
1 | import numpy as np |
Results:
y= tensor(0.) ; x= tensor(1.0000)5.3 可视化参数分布
如果需要对模型的参数(一般非标量)在训练过程中的变化进行可视化,可以使用
writer.add_histogram,它能够观测张量值分布的直方图随训练步骤的变化趋势。
1 | import numpy as np |
5.4 可视化原始图像
如果我们做图像相关的任务,也可以将原始的图片在
tensorboard 中进行可视化展示。
写入一张图片
如果只写入一张图片信息,可以使用
writer.add_image。写入多张图片
如果要写入多张图片信息,可以使用
writer.add_images。
也可以用 torchvision.utils.make_grid
将多张图片拼成一张图片,然后用writer.add_image 写入。
注意,传入的是代表图片信息的 Pytorch 中的张量数据。
1 | import torch |
Results:
{'0_airplane': 0, '1_automobile': 1}5.5 可视化人工绘图
如果我们将 matplotlib 绘图的结果再
tensorboard 中展示,可以使用 add_figure.
注意,和 writer.add_image
不同的是,writer.add_figure 需要传入
matplotlib 的 figure 对象。
1 | import torch |
Results:
{'0_airplane': 0, '1_automobile': 1}1 | %matplotlib inline |
Results:

1 | writer = SummaryWriter(data_dir + 'tensorboard1') |