前文已经对数据分析的基本操作进行了学习,接下来要进行数据清洗、数据特征提取、数据重构以及数据可视化的学习。
1 Data cleaning
1.1 Load data
1 | import numpy as np |
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
1.2 Statistic description
1.2.1 查看信息
1 | data.info() |
1.2.2 缺失值
1 | data.isnull().sum() |
1 | data[['Age','Cabin','Embarked']].head(3) |
| Age | Cabin | Embarked | |
|---|---|---|---|
| 0 | 22.0 | NaN | S |
| 1 | 38.0 | C85 | C |
| 2 | 26.0 | NaN | S |
Note:数值列读取数据后,空缺值的数据类型为
float64 所以用 None
一般索引不到,比较的时候最好用 np.nan
1.2.3 填充缺失值
处理缺失值一般有:
- 用数字
0进行填充 - 用均值进行填充(针对数值型)
- 用众数进行填充(多用于非数值型)
- 用特定标识符进行填充(实际处理时特殊对待)
- 对于缺失值占比太大的列直接进行剔除
1 | data.fillna(0, inplace = True) |
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | 0 | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | 0 | S |
fillna用法从帮助文档可以知道,
fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None),fillna包含六个参数:Value: 用做填充的值Method: 包含backfill,bfill,pad,ffill,None五个值,默认为None。backfill/bfill: 用位于缺失值索引值上的有效值进行填充,直到下一个有效值。pad/ffill: 用位于缺失值索引下的有效值进行填充,直到上一个有效值。
axis: {0 or 'index', 1 or 'columns'}inplace: bool, default False
1 | df = pd.DataFrame([[np.nan, 2, np.nan, 0], |
| A | B | C | D | |
|---|---|---|---|---|
| 0 | NaN | 2.0 | NaN | 0 |
| 1 | 3.0 | 4.0 | NaN | 1 |
| 2 | NaN | NaN | NaN | 5 |
| 3 | NaN | 3.0 | NaN | 4 |
1 | df.fillna(method='ffill') |
| A | B | C | D | |
|---|---|---|---|---|
| 0 | NaN | 2.0 | NaN | 0 |
| 1 | 3.0 | 4.0 | NaN | 1 |
| 2 | 3.0 | 4.0 | NaN | 5 |
| 3 | 3.0 | 3.0 | NaN | 4 |
1.2.4 去除空值
1 | data.dropna().head(3) # 未设置 inplace参数 |
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 6 | 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S |
1.2.5 重复值
查看重复值
1
data[data.duplicated()]
PassengerId
Survived
Pclass
Name
Sex
Age
SibSp
Parch
Ticket
Fare
Cabin
Embarked
剔除重复值
1
2data = data.drop_duplicates()
data.head()PassengerId
Survived
Pclass
Name
Sex
Age
SibSp
Parch
Ticket
Fare
Cabin
Embarked
0
1
0
3
Braund, Mr. Owen Harris
male
22.0
1
0
A/5 21171
7.2500
NaN
S
1
2
1
1
Cumings, Mrs. John Bradley (Florence Briggs Th...
female
38.0
1
0
PC 17599
71.2833
C85
C
2
3
1
3
Heikkinen, Miss. Laina
female
26.0
0
0
STON/O2. 3101282
7.9250
NaN
S
3
4
1
1
Futrelle, Mrs. Jacques Heath (Lily May Peel)
female
35.0
1
0
113803
53.1000
C123
S
4
5
0
3
Allen, Mr. William Henry
male
35.0
0
0
373450
8.0500
NaN
S
1.3 Feature analysis
对数据进行初步观察后可以发现,特征主要可以分为两大类:
数值型特征:Survived ,Pclass, Age ,SibSp, Parch, Fare,其中Survived, Pclass为离散型数值特征,Age,SibSp, Parch, Fare为连续型数值特征
文本型特征:Name, Sex, Cabin,Embarked, Ticket,其中Sex, Cabin, Embarked, Ticket为类别型文本特征。
数值型特征一般可以直接用于模型的训练,但有时候为了模型的稳定性及鲁棒性会对连续变量进行离散化。文本型特征往往需要转换成数值型特征才能用于建模分析。
1.3.1 分箱操作
按平均进行分箱
将连续变量Age平均分成5个年龄段,并分别用类别变量12345表示
1
2
3data['AgeBand'] = pd.cut(data['Age'], 5, labels = [1, 2, 3, 4, 5])
data.head(2)PassengerId
Survived
Pclass
Name
Sex
Age
SibSp
Parch
Ticket
Fare
Cabin
Embarked
AgeBand
0
1
0
3
Braund, Mr. Owen Harris
male
22.0
1
0
A/5 21171
7.2500
NaN
S
2
1
2
1
1
Cumings, Mrs. John Bradley (Florence Briggs Th...
female
38.0
1
0
PC 17599
71.2833
C85
C
3
按数值分箱
将连续变量Age划分为[0,5) [5,15) [15,30) [30,50) [50,80)五个年龄段,并分别用类别变量12345表示。
1
2data['AgeBand'] = pd.cut(data['Age'], [0, 5, 15, 30, 50, 80], labels = [1, 2, 3, 4, 5])
data.head(3)PassengerId
Survived
Pclass
Name
Sex
Age
SibSp
Parch
Ticket
Fare
Cabin
Embarked
AgeBand
0
1
0
3
Braund, Mr. Owen Harris
male
22.0
1
0
A/5 21171
7.2500
NaN
S
3
1
2
1
1
Cumings, Mrs. John Bradley (Florence Briggs Th...
female
38.0
1
0
PC 17599
71.2833
C85
C
4
2
3
1
3
Heikkinen, Miss. Laina
female
26.0
0
0
STON/O2. 3101282
7.9250
NaN
S
3
按比例分箱
将连续变量Age按10% 30% 50% 70% 90%五个年龄段,并用分类变量12345表示
1
2data['AgeBand'] = pd.cut(data['Age'], [0, 0.1, 0.3, 0.5, 0.7, 0.9], labels = [1, 2, 3, 4, 5])
data.head(3)PassengerId
Survived
Pclass
Name
Sex
Age
SibSp
Parch
Ticket
Fare
Cabin
Embarked
AgeBand
0
1
0
3
Braund, Mr. Owen Harris
male
22.0
1
0
A/5 21171
7.2500
NaN
S
NaN
1
2
1
1
Cumings, Mrs. John Bradley (Florence Briggs Th...
female
38.0
1
0
PC 17599
71.2833
C85
C
NaN
2
3
1
3
Heikkinen, Miss. Laina
female
26.0
0
0
STON/O2. 3101282
7.9250
NaN
S
NaN
1.3.2 提取字符特征
从纯文本 Name 特征里提取出 Titles 的特征(
Mr, Miss, Mrs 等)
1 | data['Title'] = data.Name.str.extract('([A-Za-z]+)\.', expand=False) |
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Sex_female | Sex_male | Embarked_C | Embarked_Q | Embarked_S | Title | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | 2 | 0 | 1 | 0 | 0 | 1 | Mr |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | 1 | 1 | 0 | 1 | 0 | 0 | Mrs |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | 2 | 1 | 0 | 0 | 0 | 1 | Miss |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | 2 | 1 | 0 | 0 | 0 | 1 | Mrs |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | 2 | 0 | 1 | 0 | 0 | 1 | Mr |
1.4 Type transformation
查看文本变量的信息。
value_counts1
2
3
4
5data['Sex'].value_counts()
male 577
female 314
Name: Sex, dtype: int64unique1
2
3data['Sex'].unique()
array(['male', 'female'], dtype=object)
1.4.1 判别式方式
将性别转换未数值型数据,用 0 表示男性,1 表示女性。
1 | data = data_copy.copy() |
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | 0 | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 1 | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | 1 | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
1.4.2 replace 方法:
1 | data = data_copy.copy() |
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Sex_num | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 1 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 2 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 2 |
1.4.3 map 方法
1 | data = data_copy.copy() |
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Sex_num | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 1 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 2 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 2 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 2 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 1 |
1.4.4 labelEncoder
使用sklearn.preprocessing.labelEncoder
1 | from sklearn.preprocessing import LabelEncoder |
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Cabin_labelEncode | Ticket_labelEncode | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 0.0 | 0 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1.0 | 1 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 0.0 | 2 |
其中,label_dict 是个字典类型,其 key
值表示真实值,即 data[feat].unique(),而对应的数值为
range(data[feat].nunique() 产生的序列。
一点小差异:
从上述代码可以发现,有两种实现方式:
map方式1
2
3data[feat].map(label_dict).values[:5]
array([0, 1, 2, 3, 4], dtype=int64)labelEncoder方式1
2
3lbl.fit_transform(data[feat].astype(str))[:5]
array([523, 596, 669, 49, 472])
Note:
可以发现,虽然两种方式都能产生同样的效果,当时生成数值编码的方式存在些许差异,第一种方式为按顺序生成,第二种会打乱顺序。
1.4.5 ont-hot 编码
1 | data = data_copy.copy() |
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | Sex_female | Sex_male | Embarked_C | Embarked_Q | Embarked_S | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 0 | 1 | 0 | 0 | 1 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1 | 0 | 1 | 0 | 0 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 1 | 0 | 0 | 0 | 1 |
对于 age,可考虑如下的方式进行处理。
整除
1
pd.get_dummies(data["Age"] // 6)[:5]
0.0
1.0
2.0
3.0
4.0
5.0
6.0
7.0
8.0
9.0
10.0
11.0
12.0
13.0
0
0
0
0
1
0
0
0
0
0
0
0
0
0
0
1
0
0
0
0
0
0
1
0
0
0
0
0
0
0
2
0
0
0
0
1
0
0
0
0
0
0
0
0
0
3
0
0
0
0
0
1
0
0
0
0
0
0
0
0
4
0
0
0
0
0
1
0
0
0
0
0
0
0
0
分箱
1
pd.get_dummies(pd.cut(data['Age'],5))[:5]
(0.34, 16.336]
(16.336, 32.252]
(32.252, 48.168]
(48.168, 64.084]
(64.084, 80.0]
0
0
1
0
0
0
1
0
0
1
0
0
2
0
1
0
0
0
3
0
0
1
0
0
4
0
0
1
0
0
2 Data reconstruction
前面已经学习了 Pandas
基础和数据清洗,只有数据变得相对干净,之后对数据的分析才可以更有力。本节要做的是数据重构,数据重构依旧属于数据理解(准备)的范围。
2.1 Data merge
数据合并内容之前已经进行了详细的记录,此处便不进行赘述,具体可以查看本人的博客内容,链接: Pandas的Chaper 4 Merge dataframes
2.2 Aggregae operation
计算男女平均票价
1
2
3
4
5
6
7fare_sex = data['Fare'].groupby(data['Sex'])
fare_sex.mean()
Sex
female 44.479818
male 25.523893
Name: Fare, dtype: float64计算男女存活人数
1
2
3
4
5
6data['Survived'].groupby(data['Sex']).sum()
Sex
female 233
male 109
Name: Survived, dtype: int64
结论:可以发现,女性票价远大于男性,其次,女性存活率大于男性。
2.2.1 Aggregate 函数
此外,上述操作还可以通过 agg 函数进行计算。
1 | data.groupby('Sex').agg({'Fare': 'mean', 'Pclass': 'count'}).rename(columns= |
| mean_fare | count_pclass | |
|---|---|---|
| Sex | ||
| female | 44.479818 | 314 |
| male | 25.523893 | 577 |
Note:
agg() 函数主要有两个参数:
func: function, str, list or dict. Function to use for aggregating the data. If a function, must eitherwork when passed a DataFrame or when passed to DataFrame.apply. e.g. mean, median, prod, sum, std, var.axis: default is 0 or 'index', operating based on all columns.
2.2.2 其他函数
统计不同等级的票中,不同年龄的船票花费的平均价格
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15data.groupby(['Pclass','Age'])['Fare'].mean()
Pclass Age
1 0.92 151.5500
2.00 151.5500
4.00 81.8583
11.00 120.0000
14.00 120.0000
...
3 61.00 6.2375
63.00 9.5875
65.00 7.7500
70.50 7.7500
74.00 7.7750
Name: Fare, Length: 182, dtype: float64不同年龄的存活人数
得出不同年龄的总的存活人数,然后找出存活人数的最高的年龄,最后计算存活人数最高的存活率(存活人数/总人数)
1
2
3
4
5
6
7
8
9
10survived_age = data['Survived'].groupby(data['Age']).sum()
survived_age.head()
Age
0.42 1
0.67 1
0.75 2
0.83 2
0.92 1
Name: Survived, dtype: int641
2
3
4
5survived_age[survived_age.values == survived_age.max()]
Age
24.0 15
Name: Survived, dtype: int64总人数:
1
2
3data['Survived'].sum()
3421
2
3
4sum_temp = data['Survived'].sum()
print('最大存活率为:{}'.format(survived_age.max()/sum_temp))
最大存活率为:0.043859649122807015
2.3 Stack to series
1 | data.stack() |
探究 stack 函数的功能:
1 | data.stack().shape |
1 | >>> unit_result.head() |
1 | print(891*18) |
可以发现,stack
函数的作用是将数据表中的每一行都转化为一个 Series,共计
891 个 Series,其形状为 15172
行,我们注意到 891 \times 18 =
16038,之间相差一些,是因为 data
中存在部分缺失值。
3 Data visualization
前文中,已经对基本数据结构有了了解,也学了一些基本的统计方法、数据清洗和重构。本章节中主要学习
数据可视化,主要给大家介绍一下 Python
数据可视化库 Matplotlib。
本章节的内容可以通过查阅 《Python for Data Analysis》第九章 进行更深入的学习。
Import modules
1
2%matplotlib inline
import matplotlib.pyplot as plt
3.1 柱状图
3.1.1 简单柱状图
可视化展示泰坦尼克号数据集中男女中生存人数分布情况。
生存情况
由于
Survived = 0表示死亡,Survived = 1表示生存,所以使用sum函数可以统计生存人数情况。1
2
3
4sex = data.groupby('Sex')['Survived'].sum()
sex.plot.bar()
plt.title('survived_count')
plt.show()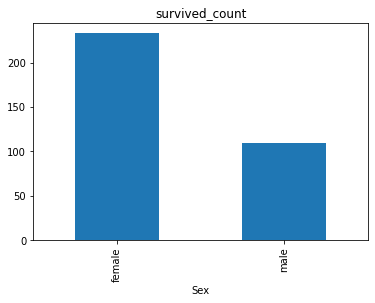
死亡情况
对于死亡人数,可以使用判别式
data['Survived'] != 1来得到死亡人数的索引,之后用count函数进行人数统计。1
2
3
4sex = data[data['Survived'] != 1].groupby('Sex').Survived.count()
sex.plot.bar()
plt.title('survived_count')
plt.show()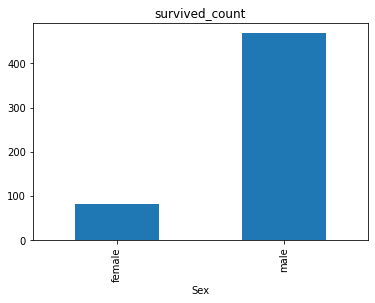
合并分析
1
2
3
4
5data.groupby(['Sex','Survived'])['Survived'].count().unstack().plot(kind='bar',stacked='True')
plt.title('survived_count')
plt.ylabel('count')
Text(0, 0.5, 'count')
1
data.groupby(['Sex','Survived'])['Survived'].count().unstack()
Survived
0
1
Sex
female
81
233
male
468
109
1
2
3
4
5
6
7
8data.groupby(['Sex','Survived'])['Survived'].count()
Sex Survived
female 0 81
1 233
male 0 468
1 109
Name: Survived, dtype: int64
Note:
上文简单介绍了 stack
函数,是将整个数据表的每一行转化为一个
pd.Series,而在此处,通过对比上述两行代码,可以发现,unstack()
的作用是反向操作,将 count 函数得到的 Series
转化为 pd.DataFrame 类型。
3.2.1 分层柱状图
可视化展示泰坦尼克号数据集中不同仓位等级的人生存和死亡人员的分布情况。
1 | >>> pclass_sur = text.groupby(['Pclass'])['Survived'].value_counts() |
1 | import seaborn as sns |
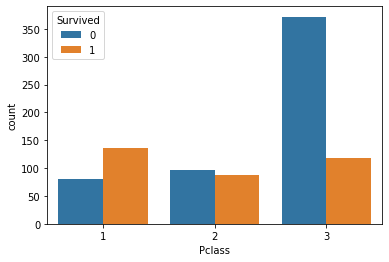
3.2 折线图
3.2.1 普通折线图
可视化展示泰坦尼克号数据集中不同票价的人生存和死亡人数分布情况(横轴是不同票价,纵轴是存活人数)。
1 | fare_sur = data.groupby('Fare')['Survived'].value_counts().sort_values(ascending = False) |
1 | # 排序后绘折线图 |
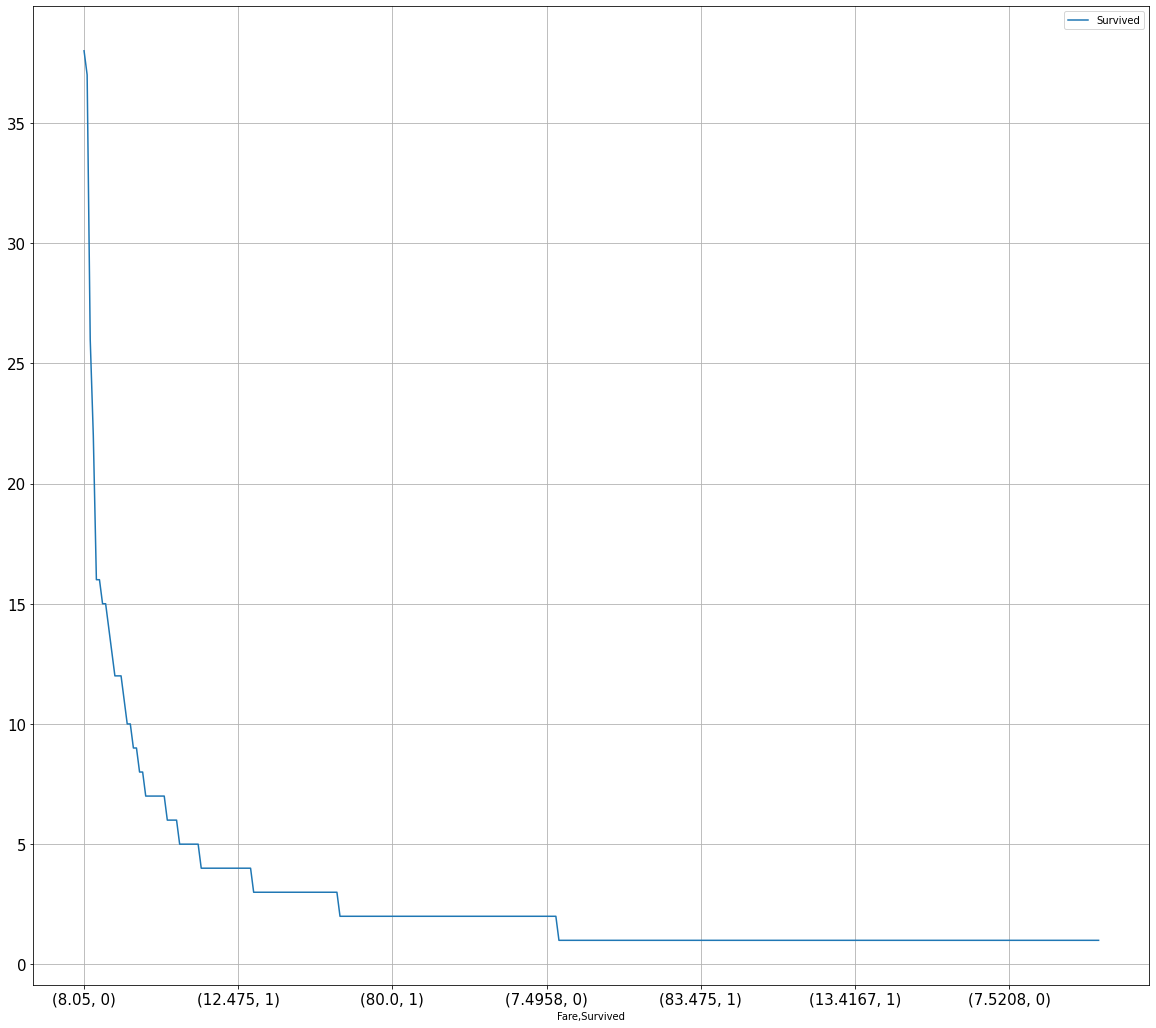
3.2.2 核密度图
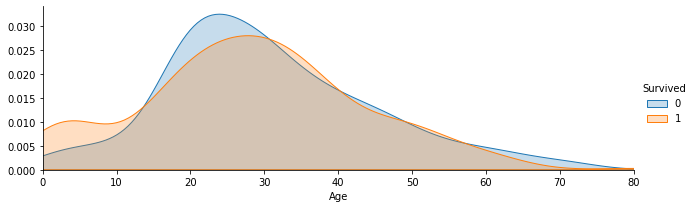
可视化展示泰坦尼克号数据集中不同年龄的人生存与死亡人数分布情况
1 | facet = sns.FacetGrid(text, hue="Survived",aspect=3) |
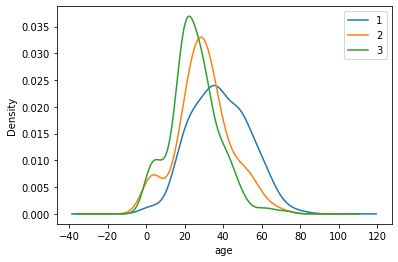
3.2.3 多个图形
1 | data.Age[data.Pclass == 1].plot(kind='kde') |
Note:
到这里,可视化就告一段落啦,后期可进一步了解其他可视化模块,如:pyecharts,bokeh
等。