1. Introduction
1.1 Job description
本项目为企查查注册企业信息爬取,项目来源是别人的实验需求。故本博客会对项目的具体数据进行脱敏处理,其中涉及的 1168 个链接本文不进行提供,也不提供成品数据。
读者如需类似信息,可以借助本博客提供的方法自行爬取。注:部分公司和企业家信息需要 VIP 账户方能进行爬取。
免责声明:本文仅供参考和交流,仅记录数据爬取过程中所使用的方法和问题的解决方法,如有侵权,请联系
e-mail:yangsuoly@qq.com。
任务爬取所需工具:
- 企查查 VIP 账户
- Python 3.8
1.2 Task requirements
网站:企查查(共1168个链接-Excel表),链接样例: https://www.qcc.com/pl/p43ce90f8f80f49f4089ab2e9040dece.html
1.2.1 企业家信息
所有企业表
抓取企业家在哪些企业有股份(即他的所有企业表,如下图所示):抓取的内容包括序号、企业名称、企业名称对应的url(第二个任务会用到)以及其余的整个表的内容。
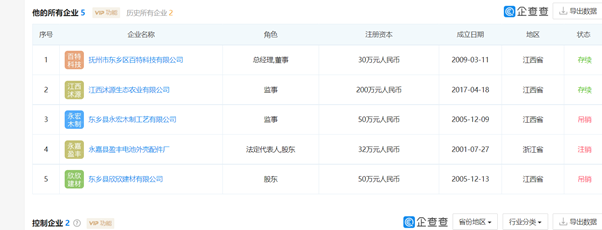
Fig. 1 所有企业表
在外任职表
抓取企业家在哪些企业有管理职位(在外任职表,如下图所示):同样的抓取的内容包括序号、企业名称以及对应的url、以及职位等表格内容。

Fig. 2 在外任职表
1.2.2 公司信息
爬取企业家旗下每一家企业信息(即他的所有企业表中的所有公司的信息,如 Fig.1 所示)的信息:
营业执照信息
企业的基本注册信息
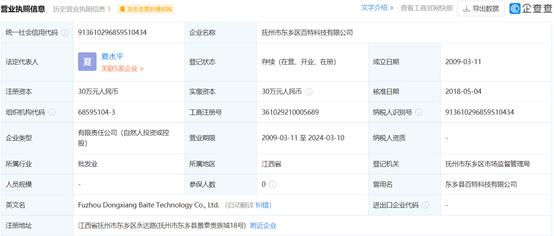
Fig. 3 营业执照信息
股东信息
企业的股东信息(点击url显示如下表),包括:每一位股东的名字 + 股份 + 每一位股东的URL
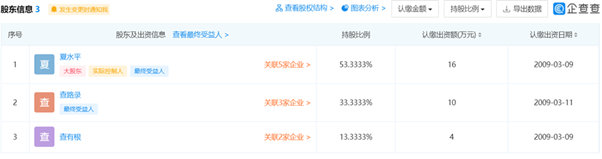
Fig. 4 公司股东信息
主要人员
企业管理者信息,包括:名字 + 股份(if applicable) + 职务 +每一位管理者的URL
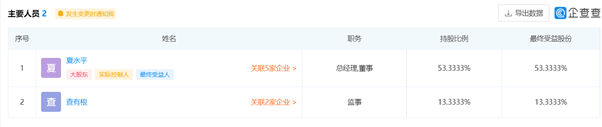
Fig. 5 主要人员信息
1.2.3 公司知识产权信息
企业的知识产权信息(点击相同url后,点击知识产权)
专利信息
包含专利信息一栏的所有信息

Fig. 6 专利信息
软件著作权
包含软件著作权一栏的所有信息
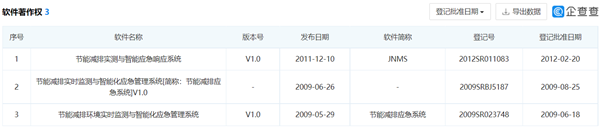
其他
如资质证书、作品著作权。
2 Static crawler
在爬取之前,对需要爬取的链接进行初步地分析,我们发现,索要爬取的信息存在如下特点:
- 大多数内容数量少于 10 条,少部分公司的词条(如专利证书)数量会大于10。
- 高管的
url链接都以pl开头,公司的基本信息的url以cbase开头,而知识产权信息以cassets开头。 - 各项信息在网页中(如果存在该词条)存在都有规律,且存在一直的
id节点,因此可以通过id对元素进行定位(id是页面中唯一的标识) - 企查查的反爬虫机制较为严格,需要适用虚拟
ip和控制请求的时间来规避反爬虫,本文只是用最简单的控制请求的时间来规避爬虫机制。
得到上述信息之后,我们考虑先用静态爬虫来进行信息的提取,之后适用动态爬虫来补充遗漏的数据。同时,文中也会附上
ip 代理池的生成方法,感兴趣的可以自行适用代理池进行虚拟
ip 的设置。
2.1 Configuration
Import modules
首先导入如下模块,如果没有的,自行适用
pip install module_name进行安装。1
2
3
4
5
6
7
8
9import os
import time
import requests
import swifter
import numpy as np
import pandas as pd
from lxml import etree
from io import StringIO
from bs4 import BeautifulSoupSet request headers
设置请求头:
1
2
3
4
5
6
7
8
9
10headers = {
'Host':'www.qcc.com',
'Connection': 'keep-alive',
'Accept':r'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36",
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9',
'Cookie':"QCCSESSID= ; qcc_did= ; zg_did= ; acw_tc= ; zg_294c2ba1ecc244809c552f8f6fd2a440= ",
}由于爬取过程中需要
VIP账户的权限,因此我们适用了本地浏览器的Cookie,此处已经对Cookie信息进行脱敏,读者自行载入自己浏览器的Cookie信息,本文全程适用Google Chrome 92.0.4515.107进行数据爬取,此处以Chrome浏览器为例,其他浏览器Cookie信息载入方法大同小异。进入企查查官网,并进行登录,只有有两种方式得到
Cookie,分别法如下:利用设置
打开
all cookies and site data界面 chrome://settings/siteData,搜查qcc将搜过结果对应字段的值粘贴到上述Cookie中等号的右边(如QCCSESSID)搜索结果如下图所示:

利用开发者模式
进入企查查官网,登录之后,按
F12或右键审视打开开发者模式,依次点击Network,Fetch/XHR,之后算便点击其中一个链接,找到Headers中的cookie字段的信息,进行复制。如下图所示:
Set data path and load data
1
2pl_root_dir = r'D:\Demo\work\XMU\Data_Collection\Results\Results/'
pd_firm = pd.read_csv('./FirmList.csv', encoding = 'ansi')其中,
FirmList.csv仅包含1168条公司url信息,由于涉及他人实验和论文信息,本文不进行公开,仅提供 5 个样本供学习交流。读者可自行寻找一些公司的url进行尝试。
2.2 自定义函数
接下来,对所需要爬取的各项数据进行拆解和爬取。
2.2.1 企业家所属信息
通过 id 我们可以定位许多信息,如
allcompanylist: 所有企业信息;postofficelist: 在外任职信息;legallist: 担任法定代表人信息;holdcolist: 控制企业
由于本项目的任务只需要前两个,故设置 n_info 为
2 爬取前两个信息。
1 | def get_pl_data(soup): |
2.2.2 公司所属信息
类似的,可以通过 id 定位公司信息:
cominfo: 营业执照信息;partner: 股东信息;mainmember: 主要人员;
1 | def get_firm_data(name_urls, sep, pl_dir): |
2.2.3 公司专利信息
zhuanlilist: 专利信息; zhengshulist:
资质证书; rjzzqlist: 软件著作权; zzqlist:
作品著作权
1 | def get_casset_data(name_urls, sep, pl_dir): |
2.2.4 建立 IP 池
可以通过如下的程序来建立个人的免费代理 IP 池子。
1 | # 建立属于自己的开放代理IP池 |
2.3 Start program
考虑到程序可能会由于异常情况而终止,我们设置了起始点,只需要对
start 的值进行更改,便可在上一次的基础上进行爬取。
1 | start = 0 # 接着上次爬取的序号 |
Result:
已经爬取0个企业家名单...
已经爬取1个企业家名单...
已经爬取2个企业家名单...
已经爬取3个企业家名单...
已经爬取4个企业家名单...
...2.4 Data cleaning
2.4.1 更正公司数量信息
1 | def get_current_dir(file_dir, all_comp_path): |
产看数和表格中的记录数是否相同
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20file_dir = 'D:\\Demo\\work\\XMU\\Data_Collection\\Results'
sep = '<break>'
error_idx = []
for i, relat_path in enumerate(pd_firm['所有企业目录'].values):
try:
name = relat_path.split('/')[2]
except:
error_idx.append(i)
print(i, relat_path, sep = '\t | \t')
continue
all_comp_path = file_dir + relat_path
all_comp = pd.read_csv(all_comp_path, encoding = 'ansi')
cur_dir = get_current_dir(file_dir, all_comp_path)
sub_dirs = os.listdir(cur_dir)
records_len = all_comp.shape[0]
if (len(sub_dirs) - 2 != records_len):
error_idx.append(i)
print(i, relat_path, sep = '\t | \t')Result:
683 | nan 747 | /Results/747.朱俊/朱俊-所有企业表.csv 868 | /Results/868.杨大伟/杨大伟-所有企业表.csv 991 | /Results/991.刘学高/刘学高-所有企业表.csv可以发现有4个数据表格中的企业数和爬取的不同。
1
pd_firm.loc[error_idx, 'url'].values
Results:
array(['https://www.qcc.com/pl/pr06c1505288f0c2021d813c9e7f332f.html', 'https://www.qcc.com/pl/pc73f5a2f9eb17be99d0ef4cf0f0991b.html', 'https://www.qcc.com/pl/pa26bc685636ad55bc1a11b5b7d42828.html', 'https://www.qcc.com/pl/p12d778b91113fa1209cdb2394bb4a65.html'], dtype=object)进一步查看发现:
- 683 孙月洋 信息缺失
- 747 朱俊 旗下两家公司信息重叠
- 868 杨大伟 旗下两家公司信息重叠
- 991 刘学高 旗下两家公司信息重叠
因此对后面三家进行重新爬取
重新爬取三个企业家的信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31file_dir = 'D:\\Demo\\work\\XMU\\Data_Collection\\Results'
sep = '<break>'
for i, relat_path in enumerate(pd_firm['所有企业目录'].values[error_idx[2:]]):
name = relat_path.split('/')[2]
all_comp_path = file_dir + relat_path
all_comp = pd.read_csv(all_comp_path, encoding = 'ansi')
pl_dir = file_dir+'/Results/' + name
# 爬取所有企业信息
all_comp['Name_com'] = all_comp['企业名称'] + sep + (all_comp['url'])
cur_dir = get_current_dir(file_dir, all_comp_path)
sub_dirs = os.listdir(cur_dir)
for j, x in enumerate(all_comp['Name_com'].values):
if x.split(sep)[0] in sub_dirs:
continue
else:
all_comp.loc[j, 'Firm_info'] = str(get_firm_data(x, sep, pl_dir))
all_comp.loc[j, 'Casset_info'] = str(get_casset_data(x, sep, pl_dir))
all_comp['股东数'] = all_comp['Firm_info'].apply(lambda x: eval(x)[list(eval(x).keys())[0]])
all_comp['主要人员数'] = all_comp['Firm_info'].apply(lambda x: eval(x)[list(eval(x).keys())[1]])
all_comp['专利信息数'] = all_comp['Casset_info'].apply(lambda x: eval(x)[list(eval(x).keys())[0]])
all_comp['资质证书数'] = all_comp['Casset_info'].apply(lambda x: eval(x)[list(eval(x).keys())[1]])
all_comp['软件著作权数'] = all_comp['Casset_info'].apply(lambda x: eval(x)[list(eval(x).keys())[2]])
all_comp['作品著作权数'] = all_comp['Casset_info'].apply(lambda x: eval(x)[list(eval(x).keys())[3]])
all_comp_path = pl_dir + f'/{name}-所有企业表.csv'
all_comp.drop('Name_com', axis = 1).to_csv(all_comp_path, encoding = 'ansi', index = False)
time.sleep(5)
2.4.2 数据规范化
查看数据
1 | pd_firm.sample(5) |
| url | 企业家名字 | 在外任职目录 | 所有企业目录 | |
|---|---|---|---|---|
| 454 | https://www.qcc.com/pl/pc0bf5ac0db3ac3833528e9... | 徐诵舜 | /Results/454.徐诵舜/徐诵舜-在外任职表.csv | /Results/454.徐诵舜/徐诵舜-所有企业表.csv |
| 444 | https://www.qcc.com/pl/pe9f1e4541b32c30c40c4f1... | 刘键 | /Results/444.刘键/刘键-在外任职表.csv | /Results/444.刘键/刘键-所有企业表.csv |
| 244 | https://www.qcc.com/pl/p103fd20dc779066987fd98... | 刘兵 | /Results/244.刘兵/刘兵-在外任职表.csv | /Results/244.刘兵/刘兵-所有企业表.csv |
| 610 | https://www.qcc.com/pl/p4f922b492f237793f8e240... | 刘云辉 | /Results/610.刘云辉/刘云辉-在外任职表.csv | /Results/610.刘云辉/刘云辉-所有企业表.csv |
| 1146 | https://www.qcc.com/pl/p98067b26718f4c7b0b9e69... | 李骁淳 | /Results/1146.李骁淳/李骁淳-在外任职表.csv | /Results/1146.李骁淳/李骁淳-所有企业表.csv |
1 | ignore_index = pd_firm[pd_firm['企业家名字'].isnull()].index |
Result:
array([], shape=(0, 4), dtype=object)可以发现,数据爬取基本成功,接下来对文件目录进行标准化,方便迁移分析。
Modify file path
将文件路径的绝对路劲转换为相对路径。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def mode_path(path):
if isinstance(path, float):
return path
if path.startswith('.'):
modify_path = path[1:]
elif path.startswith('D:\\'):
path_split = path.split('D:\\Demo\\work\\XMU\\Data_Collection\\Results\\')
modify_path = '/' + path_split[1]
elif path.startswith('/'):
modify_path = path
return modify_path
import swifter # 加速apply
pd_firm['在外任职目录'] = pd_firm['在外任职目录'].swifter.apply(mode_path)
pd_firm['所有企业目录'] = pd_firm['所有企业目录'].swifter.apply(mode_path)Recheck
1 | file_dir = 'D:\\Demo\\work\\XMU\\Data_Collection\\Results' |
Result:
683 | nan至此处理完毕,公司数和表格中的记录数能对上。其中683为失效链接,后续直接去掉:
1 | pd_firm = pd_firm.drop(683, axis = 0) |
2.4.3 更新专利信息
更新所有数量信息
1 | file_dir = 'D:\\Demo\\work\\XMU\\Data_Collection\\Results' |
Modify path
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22def mod_name(x):
if '.' in x:
name = x.split('.')[1]
else:
name = x
return name
def mode_path(path):
if isinstance(path, float):
return path
if path.startswith('.'):
modify_path = path[1:]
elif path.startswith('D:'):
path_split = path.split('D:\Demo\work\XMU\Data_Collection\Results/')
modify_path = '/' + path_split[1]
elif path.startswith('/'):
modify_path = path
return modify_path
pd_pl_comp['企业家名字'] = pd_pl_comp['企业家名字'].apply(mod_name)
pd_pl_comp['公司目录'] = pd_pl_comp['公司目录'].swifter.apply(mod_name)
pd_pl_comp.rename(columns={'url':'Com_url','b':'B'}, inplace = True)Merge
1
2pd_all_firm = pd_firm.copy()
pd_all_firm = pd.merge(pd_all_firm, pd_pl_comp, on = '企业家名字', how = 'outer')
核对数量
产看所有信息指标
1
pd_all_firm.columns
Results:
Index(['url', '企业家名字', '在外任职目录', '所有企业目录', '序号', '企业名称', '角色', '注册资本', '成立日期', '地区', '状态', 'Com_url', 'Firm_info', 'Casset_info', '股东数', '主要人员数', '专利信息数', '资质证书数', '软件著作权数', '作品著作权数', 'Name_com', '公司目录', 'Name'], dtype='object')Check
由于静态爬取仅能爬取页面中加载的第一页信息,共十条,因此对所爬取的信息数量进行核对,对所爬取的
csv表格中信息数为 10 的进行动态爬取,补充信息。1
2
3
4
5
6
7
8check_names = [ '股东数', '主要人员数', '专利信息数', '资质证书数', '软件著作权数', '作品著作权数']
for col in check_names:
col_shape = pd_all_firm[pd_all_firm[col]>=10].shape
print(col, col_shape, sep = ' | ')
for col in check_names:
col_shape = pd_all_firm[pd_all_firm[col]>10].shape
print(col, col_shape, sep = ' | ')Result:
股东数 | (658, 23) 主要人员数 | (225, 23) 专利信息数 | (1009, 23) 资质证书数 | (411, 23) 软件著作权数 | (576, 23) 作品著作权数 | (15, 23) 股东数 | (585, 23) 主要人员数 | (162, 23) 专利信息数 | (0, 23) 资质证书数 | (0, 23) 软件著作权数 | (0, 23) 作品著作权数 | (0, 23)可以发现资产信息的四个指标的数量基本都是10个,这些都需要进行重新爬取。接下来需要适用动态爬虫来对这些信息进行补充。
Save
1
pd_all_firm.to_csv('./All_pd_firm.csv', encoding = 'ansi', index = True)
3. Dynamic crawler
3.1 Problem description
尽管上述静态爬虫能爬取绝大多数的信息,但还是存在诸多问题,如:所有企业表中:以 高波 为例,北京 *** 科技有限责任公司为例,所有企业表中的专利数等信息存在错误。<所有企业表> 中的专利信息数和资质证书数都错了。
经过分析,发现造成这些原因是因为静态爬虫不能得到页面内动态加载的信息(指同一个
url 中点击按钮后会加载不同的信息),因此在本节中,我们考虑用
selenium
来进行动态爬取资产信息,补充第二节中静态爬虫未能完整爬取的信息。
3.2 Configuration
由于本人使用的是 Google Chrome 浏览器,其版本是
92.0.4515.107。因此在本节中,我们借助 selenium
库中的 webdriver
驱动进行动态爬取,使用该工具需要下载相应的驱动,其各版本的驱动可以通过
华为镜像
进行下载,需要注意的是要下载自己浏览器对应的驱动版本,同时将该文件所保存的地址传给
executable_path 参数,如本人的存储地址为:
1 | C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe |
Import modules
同上,若未安装对应的库,可使用
pip install module_name进行安装。1
2
3
4
5
6
7
8
9
10
11
12
13import sys
import time # 提供延时功能
import numpy as np
import os
import json
import pickle
import requests
import pandas as pd
from urllib.parse import urlencode
from bs4 import BeautifulSoup
from io import StringIO
from selenium import webdriver # 浏览器操作库Launch driver
1
2
3
4
5
6
7
8
9
10option = webdriver.ChromeOptions()
option.add_argument(
'--user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36"')
driver = webdriver.Chrome(
options=option, executable_path='C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
# 打开登录页面
driver.get('https://www.qcc.com/')
time.sleep(20) # 等待20s,完成手动登录操作
driver.refresh()可以注意到在这里我们休眠了 20 s,这个过程是为了手动用企查查
APP进行扫码登录,虽然也可以传入cookie进行登录,不过本人在传入cookie过程中并未成功,因此使用该简便方式进行登录。Load data
1
2
3
4pl_root_dir = r'D:\Demo\work\XMU\Data_Collection\Results/'
pd_all_firm = pd.read_csv('./All_pd_firm.csv', encoding='ansi', index_col = 0)
pd_firm = pd.read_csv('FirmList.csv', encoding='ansi')
3.3 Data complementary
对数量不对的进行再次爬取,先获取数量不对的条目的index
得到需要重新爬取的数据索引
得到需要重新爬取的数据
1
2
3
4
5
6
7
8
9
10check_names = ['股东数', '主要人员数', '专利信息数', '资质证书数', '软件著作权数', '作品著作权数']
recheck_index = pd.Index([])
recheck_type_index = []
for col in check_names[2:]:
check_idx = pd_all_firm[pd_all_firm[col] >= 10].index
recheck_index = recheck_index.append(check_idx)
recheck_type_index.append(check_idx)
recheck_index = list(set(recheck_index))判断当前节点是否存在
由于有些信息节点并不是所有企业都有(如知识产权),因此我们需要判断该节点是否存在,以防程序报错而终止运行。
我们可以通过
type_input来控制传入的节点的类型,如xpath,tag等,也可以自行扩充。1
2
3
4
5
6
7
8
9def NodeExists(drievr, input_code, type_input):
try:
if type_input == 'xpath':
driver.find_element_by_xpath(input_code)
elif type_input == 'tag':
driver.find_element_by_tag_name(input_code)
return True
except:
return False判断四个信息中哪些信息需要重新爬取
通过筛选之后,我们发现在外任职表和所有企业表的信息基本准确,因此,主要针对专利信息、资质证书、软件著作权和作品著作权进行更新。
此外,我们需要判断四个节点中有哪些节点是需要更新的,因为并不是所有的节点都需要更新,全部更新的话颇为耗时,且有报错的可能。
1
2
3
4
5
6def check_idx(pd_data, idx, recheck_cols):
ret_idx = []
for i, col in enumerate(recheck_cols):
if pd_data.loc[idx, col] >= 10:
ret_idx.append(i)
return ret_idx开始更新数据
得到需要更新的数据的索引
recheck_index之后,我们对这些数据进行遍历和爬取。由于不同节点的xpath地址不同,我们使用if ... else ...语句进行区分对待。最后将更新好的数据保存至All_pd_firm-mod.csv文件中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151start_pos = 0
for idx, i in enumerate(recheck_index[start_pos:]):
name = pd_all_firm.loc[i, '企业名称']
casset_path = pd_all_firm.loc[i, '公司目录']
url = pd_all_firm.loc[i, 'Com_url']
firm_url = url.split('firm')
url = firm_url[0] + 'cassets' + firm_url[1]
# requests.get(url=url, cookies=cookies, headers=headers, timeout=5).text
driver.get(url)
time.sleep(3)
'''专利信息:zhuanlilist
资质证书:zhengshulist
软件著作权:rjzzqlist
作品著作权:zzqlist
'''
list_ids = ['zhuanlilist', 'zhengshulist', 'rjzzqlist', 'zzqlist']
num_cassets_id = [1, 1, 0, 0]
cas_keys = ['专利信息', '资质证书', '软件著作权', '作品著作权'] # csv表名称
recheck_cols = ['专利信息数', '资质证书数', '软件著作权数', '作品著作权数'] # 数量
cas_numbers = [0, 0, 0, 0]
dic_cassets = dict(zip(cas_keys, cas_numbers))
# if os.path.exists(pl_root_dir+casset_path):
# pass
# else:
# os.makedirs(casset_path)
recheck_col_idx = check_idx(pd_all_firm, i, recheck_cols)
# pd_all_firm.loc[i, recheck_cols]
for j in recheck_col_idx:
com_id = list_ids[j]
casset_dir = pl_root_dir + casset_path + cas_keys[j] + '.csv'
# try:
html_table = driver.find_element_by_id(com_id).get_attribute("innerHTML") # 专利信息
soup = BeautifulSoup(html_table, 'lxml')
if j == 0:
# 专利信息
txt = soup.find('div', class_='app-ntable')
pd_comp = pd.read_html(StringIO(str(txt)))[0] # 专利信息
number_xpath = '//*[@id="zhuanlilist"]/div[4]/nav/ul'
if NodeExists(driver, number_xpath, 'xpath'):
while 1 :
try:
list_str_list = driver.find_element_by_xpath(number_xpath).text
bt_text = list_str_list.split(' ')
bt_next_index = bt_text.index('>') + 1
except:
break
bt_xpath = f'//*[@id="zhuanlilist"]/div[4]/nav/ul/li[{bt_next_index}]'
driver.find_element_by_xpath(bt_xpath).click()
time.sleep(0.5)
html_table = driver.find_element_by_id(com_id).get_attribute("innerHTML") # 专利信息
soup = BeautifulSoup(html_table, 'lxml')
tmp_txt = soup.find('div', class_='app-ntable')
tmp_pd_comp = pd.read_html(StringIO(str(tmp_txt)))[0] # 专利信息
pd_comp = pd.concat([pd_comp, tmp_pd_comp], axis = 0)
elif j == 1:
pd_comp = pd.read_html(StringIO(str(html_table)))[0] # 得到公司信息
casset_driver = driver.find_element_by_id(com_id)
table_cas = casset_driver.find_element_by_class_name('app-ntable')
if NodeExists(table_cas, 'nav', 'tag'):
while 1 :
try:
number_xpath = '//*[@id="zhengshulist"]/div[4]/div[2]/nav/ul'
# list_str_list = table_cas.find_element_by_xpath(number_xpath).text
list_str_list = table_cas.find_element_by_tag_name('nav').text
bt_text = list_str_list.split(' ')
bt_next_index = bt_text.index('>') + 1
except:
break
bt_xpath = f'//*[@id="zhengshulist"]/div[4]/div[2]/nav/ul/li[{bt_next_index}]'
table_cas.find_element_by_xpath(bt_xpath).click()
time.sleep(0.5)
html_table = driver.find_element_by_id(com_id).get_attribute("innerHTML") # 专利信息
soup = BeautifulSoup(html_table, 'lxml')
tmp_txt = soup.find('div', class_='app-ntable')
tmp_pd_comp = pd.read_html(StringIO(str(tmp_txt)))[0] # 专利信息
pd_comp = pd.concat([pd_comp, tmp_pd_comp], axis = 0)
elif j == 2:
pd_comp = pd.read_html(StringIO(str(html_table)))[0] # 得到公司信息
casset_driver = driver.find_element_by_id(com_id)
table_cas = casset_driver.find_element_by_class_name('app-ntable')
if NodeExists(table_cas, 'nav', 'tag'):
while 1 :
try:
number_xpath = '//*[@id="rjzzqlist"]/div[2]/nav/ul'
# list_str_list = table_cas.find_element_by_xpath(number_xpath).text
list_str_list = table_cas.find_element_by_tag_name('nav').text
bt_text = list_str_list.split(' ')
bt_next_index = bt_text.index('>') + 1
except:
break
bt_xpath = f'//*[@id="rjzzqlist"]/div[2]/nav/ul/li[{bt_next_index}]'
table_cas.find_element_by_xpath(bt_xpath).click()
time.sleep(0.5)
html_table = driver.find_element_by_id(com_id).get_attribute("innerHTML") # 专利信息
soup = BeautifulSoup(html_table, 'lxml')
tmp_txt = soup.find('div', class_='app-ntable')
tmp_pd_comp = pd.read_html(StringIO(str(tmp_txt)))[0] # 专利信息
pd_comp = pd.concat([pd_comp, tmp_pd_comp], axis = 0)
elif j == 3:
pd_comp = pd.read_html(StringIO(str(html_table)))[0] # 得到公司信息
casset_driver = driver.find_element_by_id(com_id)
table_cas = casset_driver.find_element_by_class_name('app-ntable')
if NodeExists(table_cas, 'nav', 'tag'):
while 1 :
try:
number_xpath = '//*[@id="zzqlist"]/div[2]/nav/ul'
# list_str_list = table_cas.find_element_by_xpath(number_xpath).text
list_str_list = table_cas.find_element_by_tag_name('nav').text
bt_text = list_str_list.split(' ')
bt_next_index = bt_text.index('>') + 1
except:
break
bt_xpath = f'//*[@id="zzqlist"]/div[2]/nav/ul/li[{bt_next_index}]'
table_cas.find_element_by_xpath(bt_xpath).click()
time.sleep(0.5)
html_table = driver.find_element_by_id(com_id).get_attribute("innerHTML") # 专利信息
soup = BeautifulSoup(html_table, 'lxml')
tmp_txt = soup.find('div', class_='app-ntable')
tmp_pd_comp = pd.read_html(StringIO(str(tmp_txt)))[0] # 专利信息
pd_comp = pd.concat([pd_comp, tmp_pd_comp], axis = 0)
pd_all_firm.loc[i, recheck_cols[j]] = pd_comp.shape[0]
pd_comp.to_csv(casset_dir, encoding = 'ansi', index = False, errors = 'ignore')
time.sleep(2)
print(f'第{idx+start_pos}个条目已经重新整理完毕!')
pd_all_firm.to_csv('./All_pd_firm-mod.csv', encoding='ansi', errors = 'ignore')
driver.close()
至此,数量信息更新完毕,由于 selenium
是通过动态爬取,其结果很大程度上具有可信性。
4 Data Preprocess
4.1 Job description
经过动态爬取之后,为了方便做研究,甲方认为数据仍然存在些许需要改善的地方,因此本节的主要目的是对得到的数据进行数据预处理。
甲方提出需求如下:
所有企业表和在外任职表:仅需要企业的url,但是把法定代表人的url也给搞下来了,造成表格较乱(处理方法两种,要不把法人url给删除了,要不把法人url给对齐,推荐后者)。如下图所示:

Fig. 7 在外任职表样例
营业执照信息表:企业名称、经营范围、英文名以及注册地址存在重复;法定代表人处存在重复的首字(注:该问题存在的原因是因为我们直接借助
pd.read_html进行页面表格的提取,而这种方式对于合并单元的处理并不友好。)。如下图所示:
Fig. 8 营业执照信息样例
如果可行,把表头方第一行,内容方第二行吧(此外,营业执照信息表里中D2单元格-有关企业名称拿里有多余”复制”两个字,需要进行剔除)。
股东信息表和主要人员表:B列和C列重复,把C列中”关联?加企业”单独分出一列。

Fig. 9 营业执照信息样例
所有企业表中,需要载爬取一个数据:当企业状态为注销或吊销时,需要再爬取注销的时间,如下图所示。

Fig. 10 注销时间样例
4.2 Preprocess
在本节中,我们针对甲方提出的问题对所得到的数据进行一个个处理。
4.2.1 Task 1
首先我们定义一些函数,方便处理。
得到精确的高管名字
通过 Fig.7 我们可以发现,直接从网页上爬取的企业(家)名称并不一定精确,所以需要对这些信息进行标准化处理。
1
2
3
4
5
6def mod_plname(pl_name):
pl_list = pl_name.split(' ')
if len(pl_list[0]) == 1:
return pl_list[1]
elif len(pl_list[0]) > 1:
return pl_list[0]用字典存储企业及其 url
1
2
3
4
5
6
7
8
9
10def updata_names(dict_url):
en_keys = dict()
keys = dict_url.keys()
for ky in keys:
ky_split = ky.split(' ')
if len(ky_split) > 1:
en_keys[ky_split[0]] = ky
else:
en_keys[ky] = ky
return en_keys更新名称和url
1
2
3
4
5def mod_url(name, dict_url):
if name in dict_url.keys():
return dict_url[name]
else:
return np.nan得到关联信息
1
2
3
4
5
6
7
8
9
10def mod_connec(name):
ky_split = name.split(' ')
if len(ky_split) > 1:
connect = ky_split[-2]
if connect.startswith('关联'):
return connect
else:
return np.nan
else:
return np.nan
处理股东信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60start = 0
for i, u_idx in enumerate(pd_all_firm.index[start:]):
i = i + start
name = pd_all_firm.loc[u_idx, '企业名称']
people_path = pd_all_firm.loc[u_idx, '公司目录']
read_people_path = 'Results - Copy' + people_path.split('/Results')[1]
out_people_path = people_path
pl_csv = '股东信息.csv'
people_dir = pl_root_dir + read_people_path + pl_csv
'''
columns:
['序号', '股东名称', '股东名称.1', '持股比例',
'持股数(股)', '关联产品/机构', 'Name', 'url']
'''
if pd_all_firm.loc[u_idx, '股东数'] == 0:
break
try:
pd_people = pd.read_csv(people_dir, encoding = 'ansi')
except:
continue
numbers = pd_people['序号'].notnull().sum()
columns = pd_people.columns
pd_pl_mod = pd_people.loc[:numbers-1, columns[:-2]]
pd_pl_mod[columns[1]] = pd_pl_mod[columns[2]].apply(mod_plname)
if 'Name' in pd_people.columns:
dict_url = dict(zip(pd_people['Name'].values, pd_people['url'].values))
try:
pd_pl_mod['url'] = pd_pl_mod[columns[1]].apply(lambda x: dict_url[x])
except:
try:
dict_names = updata_names(dict_url)
pd_pl_mod[columns[1]] = pd_pl_mod[columns[1]].apply(lambda x: dict_names[x] if x in dict_names.keys() else x)
except:
keys = pd_people['Name'][0]
beg_idx = keys.index('[')
end_idx = keys.index(']')
keys = eval(keys[beg_idx:end_idx+1])
values = pd_people['url'][0]
beg_idx = values.index('[')
end_idx = values.index(']')
values = eval(values[beg_idx:end_idx+1])
dict_url = dict_url = dict(zip(keys, values))
pd_pl_mod['url'] = pd_pl_mod[columns[1]].apply(lambda x: mod_url(x, dict_url))
pd_pl_mod['关联信息'] = pd_pl_mod[(columns[2])].apply(mod_connec)
pd_pl_mod.drop(columns[2], axis = 1, inplace = True)
people_mod_dir = pl_root_dir + out_people_path + pl_csv.split('.')[0] + '-mod.csv'
pd_pl_mod.to_csv(people_mod_dir, encoding = 'ansi', index = False)
if i % 10 == 0:
print(f'第{i}条人员信息已处理完毕')处理在外任职表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45start = 0
for i, u_idx in enumerate(pd_firm.index[start:]):
i = i + start
out_dir = pd_firm.loc[u_idx, '在外任职目录']
out_path = pl_root_dir + out_dir
pd_people = pd.read_csv(out_path, encoding = 'ansi')
if pd_people.shape[0] == 0:
continue
numbers = pd_people['序号'].notnull().sum()
columns = pd_people.columns
pd_pl_mod = pd_people.loc[:numbers-1, columns[:-2]]
pd_pl_mod[columns[1]] = pd_pl_mod[columns[1]].apply(mod_plname)
if 'Name' in pd_people.columns:
dict_url = dict(zip(pd_people['Name'].values, pd_people['url'].values))
try:
pd_pl_mod['url'] = pd_pl_mod[columns[1]].apply(lambda x: dict_url[x])
except:
try:
dict_names = updata_names(dict_url)
pd_pl_mod[columns[1]] = pd_pl_mod[columns[1]].apply(lambda x: dict_names[x] if x in dict_names.keys() else x)
except:
keys = pd_people['Name'][0]
beg_idx = keys.index('[')
end_idx = keys.index(']')
keys = eval(keys[beg_idx:end_idx+1])
values = pd_people['url'][0]
beg_idx = values.index('[')
end_idx = values.index(']')
values = eval(values[beg_idx:end_idx+1])
dict_url = dict_url = dict(zip(keys, values))
pd_pl_mod['url'] = pd_pl_mod[columns[1]].apply(lambda x: mod_url(x, dict_url))
pd_pl_mod.drop(columns[2], axis = 1, inplace = True)
people_mod_dir = out_path.split('.csv')[0] + '-mod.csv'
pd_pl_mod.to_csv(people_mod_dir, encoding = 'ansi', index = False)
# break
if i % 10 == 0:
print(f'第{i}条人员信息已处理完毕')
4.2.2 工商信息处理
标准化名字
1
2
3
4
5
6
7
8
9def new_mod_plname(pl_name):
if isinstance(pl_name, str):
pl_list = pl_name.split(' ')
if len(pl_list[0]) == 1:
return pl_list[1]
elif len(pl_list[0]) > 1:
return pl_list[0]
else:
return pl_nameupdate
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79start = 366
for i, u_idx in enumerate(pd_all_firm.index[start:]):
i = i + start
name = pd_all_firm.loc[u_idx, '企业名称']
people_path = pd_all_firm.loc[u_idx, '公司目录']
pl_csv = '营业执照信息.csv'
people_dir = pl_root_dir + people_path + pl_csv
'''
columns:
['序号', '股东名称', '股东名称.1', '持股比例',
'持股数(股)', '关联产品/机构', 'Name', 'url']
'''
try:
pd_people = pd.read_csv(people_dir, encoding = 'ansi')
except:
continue
if pd_people.shape[0] == 10:
columns = pd_people.iloc[:, 0].values.tolist()
columns.extend(pd_people.iloc[:, 2].values[:7].tolist())
columns.extend(pd_people.iloc[:, 4].values[1:8].tolist())
# 第二列
idx = pd_people.iloc[:, 1].values[0].split('复制')[0].strip()
name = new_mod_plname(pd_people.iloc[:, 1].values[1])
dollar = pd_people.iloc[:, 1].values[2]
org_id = pd_people.iloc[:, 1].values[3].split('复制')[0].strip()
values = [idx, name, dollar, org_id] # id
values.extend(pd_people.iloc[:, 1].values[4:].tolist())
values.append(pd_people.iloc[:, 3].values[0].split('复制')[0].strip())
values.extend(pd_people.iloc[:, 3].values[1:3].tolist())
values.append(pd_people.iloc[:, 3].values[3].split('复制')[0].strip())
values.extend(pd_people.iloc[:, 3].values[4:7].tolist())
values.extend(pd_people.iloc[:, 5].values[1:3].tolist())
values.append(pd_people.iloc[:, 5].values[3].split('复制')[0].strip())
values.extend(pd_people.iloc[:, 5].values[4:8].tolist())
pd_pl_mod.drop(columns[2], axis = 1, inplace = True)
people_mod_dir = pl_root_dir + people_path + pl_csv.split('.')[0] + '-mod.csv'
pd_pl_mod.to_csv(people_mod_dir, encoding = 'ansi', index = False)
pd_pl_mod = pd.DataFrame(np.array(values).reshape(1,-1), columns = columns)
elif pd_people.shape[0] == 11:
columns = pd_people.iloc[:, 0].values.tolist()
columns.extend(pd_people.iloc[:, 2].values[:7].tolist())
columns.extend(pd_people.iloc[:, 4].values[1:8].tolist())
# 第二列
idx = pd_people.iloc[:, 1].values[0].split('复制')[0].strip()
name = new_mod_plname(pd_people.iloc[:, 1].values[1])
dollar = pd_people.iloc[:, 1].values[2]
org_id = pd_people.iloc[:, 1].values[3].split('复制')[0].strip()
values = [idx, name, dollar, org_id] # id
values.extend(pd_people.iloc[:, 1].values[4:].tolist())
values.append(pd_people.iloc[:, 3].values[0].split('复制')[0].strip())
values.extend(pd_people.iloc[:, 3].values[1:3].tolist())
values.append(pd_people.iloc[:, 3].values[3].split('复制')[0].strip())
values.extend(pd_people.iloc[:, 3].values[4:7].tolist())
values.extend(pd_people.iloc[:, 5].values[1:3].tolist())
values.append(pd_people.iloc[:, 5].values[3].split('复制')[0].strip())
values.extend(pd_people.iloc[:, 5].values[4:8].tolist())
pd_pl_mod.drop(columns[2], axis = 1, inplace = True)
people_mod_dir = pl_root_dir + people_path + pl_csv.split('.')[0] + '-mod.csv'
pd_pl_mod.to_csv(people_mod_dir, encoding = 'ansi', index = False)
pd_pl_mod = pd.DataFrame(np.array(values).reshape(1,-1), columns = columns)
people_mod_dir = people_dir.split('.csv')[0] + '-mod.csv'
pd_pl_mod.to_csv(people_mod_dir, encoding = 'ansi', index = False)
# break
if i % 10 == 0:
print(f'第{i}条人员信息已处理完毕')
4.2.3 股东和主要人员url匹配
从 Fig.9 可以发现,股东名字和 url 并没有很好地对应,因此对该记录进行校正,删除多余的信息,仅保留与前面合伙人一直的url信息,如果不能匹配则填充为空值。
1 | def mod_plname(pl_name): |
4.2.4 得到注销时间
此处,我们仍然使用动态爬虫的方式爬取注销时间,通过分析页面可以发现,注销的实践存储在
xpath 值为
/html/body/div[3]/div/div/div[2]/table/tr[2]/td[3]
的节点下,不过需要点击方可显示该节点。
1 | pd_all_firm = pd.read_csv('./All_pd_firm-mod.csv', encoding='ansi') |
4.2.5 更新所有数量信息
至此,我们已经对四个任务处理完毕,接下来,我们更新表格的的数量信息。
1 | columns = ['企业表', '公司地址', '公司url', '股东信息', 'NUM_股东信息', '主要人员', 'NUM_主要人员', |
4.2.6 删除旧的信息
由于在处理数据过程中,以防万一我们都用 -mod
的后缀处理得到的所有信息,因此,再甲方确认处理完的信息无误之后,我们需要对旧信息进行删除,这里需要用到文件夹操作,具体代码如下:
删除旧的公司信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16remove_name = ['股东信息.csv', '主要人员.csv', '营业执照信息.csv']
keep_name = ['股东信息-mod.csv', '主要人员-mod.csv', '营业执照信息-mod.csv']
start = 0
for i, u_idx in enumerate(pd_all_firm.index[start:]):
i = i + start
name = pd_all_firm.loc[u_idx, '企业名称']
people_path = pd_all_firm.loc[u_idx, '公司目录']
remove_name = ['股东信息.csv', '主要人员.csv', '营业执照信息.csv']
keep_name = ['股东信息-mod.csv', '主要人员-mod.csv', '营业执照信息-mod.csv']
people_dir = pl_root_dir + people_path
have_file_lists = os.listdir(people_dir)
for j in range(3):
if remove_name[j] in have_file_lists and keep_name[j] in have_file_lists:
os.remove(os.path.join(people_dir, remove_name[j]))删除多余的任职表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23pl_root_dir_new = pl_root_dir + 'Results/'
pl_dirs = os.listdir(pl_root_dir_new)
remove_name = ['在外任职表.csv', '所有企业表.csv']
keep_name = ['在外任职表-mod.csv', '所有企业表_mod.csv']
for i, tmp_dir in enumerate(pl_dirs):
if '.' in tmp_dir:
name = tmp_dir.split('.')[1]
else:
name = tmp_dir
pl_dir = pl_root_dir_new + tmp_dir
have_file_lists = os.listdir(pl_dir)
remove_names = [name+'-'+table for table in remove_name]
keep_names = [name+'-'+table for table in keep_name]
for j in range(2):
if remove_names[j] in have_file_lists and keep_names[j] in have_file_lists:
os.remove(os.path.join(pl_dir, remove_names[j]))
if i % 100 == 0:
print(f'第{i}个条目已经重新整理完毕!')
5 Conclusion
至此,所有信息处理完毕,甲方也十分满意。最后附上成品图。
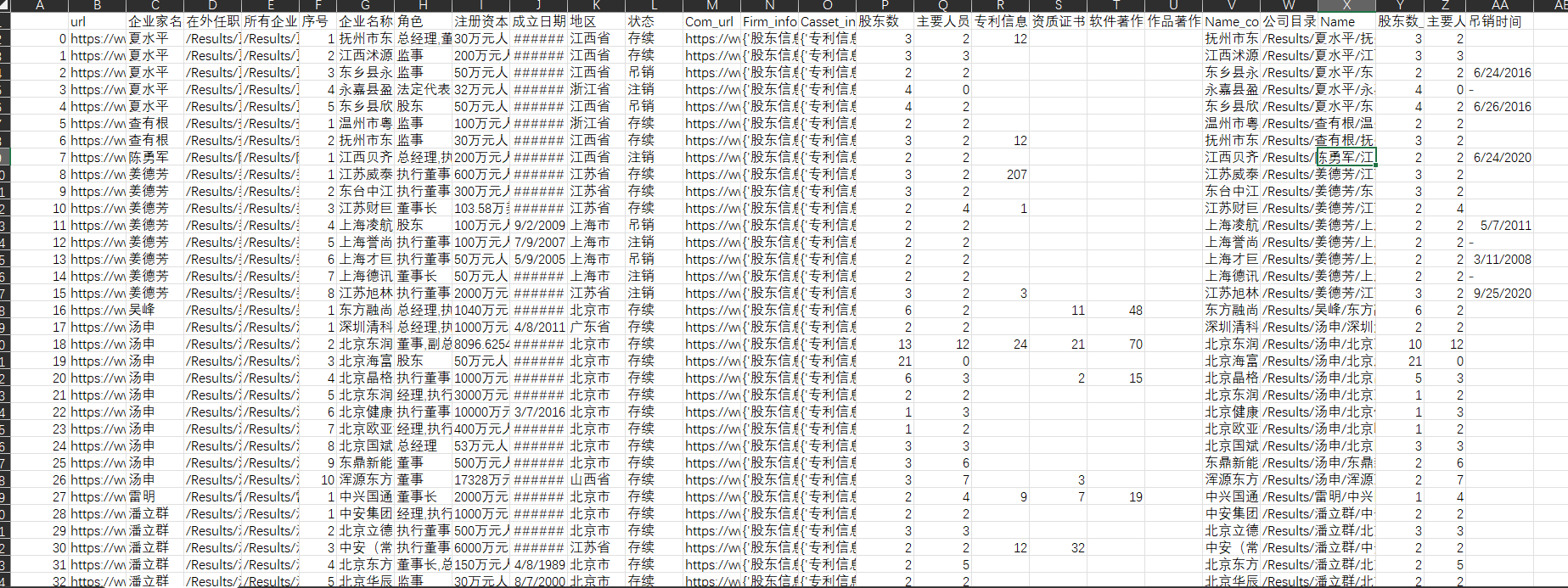
由于是别人的研究,本文不提供更详细的数据,代码已基本附上。所获取的数据仅用于研究,不做他用,展示数据已经过脱敏处理。图片皆为个人爬取后的数据截图,如有侵权,可联系邮箱进行删除。
申明:本文的代码均为个人原创,本文仅供学习和交流,请珍惜作者劳动成果,勿用作商业用途,如需商业用途或业务交流可联系邮箱
e-mail:yangsuoly@qq.com 进行进一步交流。